
Classification Optimization¶
Classification is one of the most widely used tasks in NLP. Optimizing GenAI-based classification can help developers quickly create a well-performing model. In the long term, this model can also help bootstrap the training of a more cost-effective classification model.
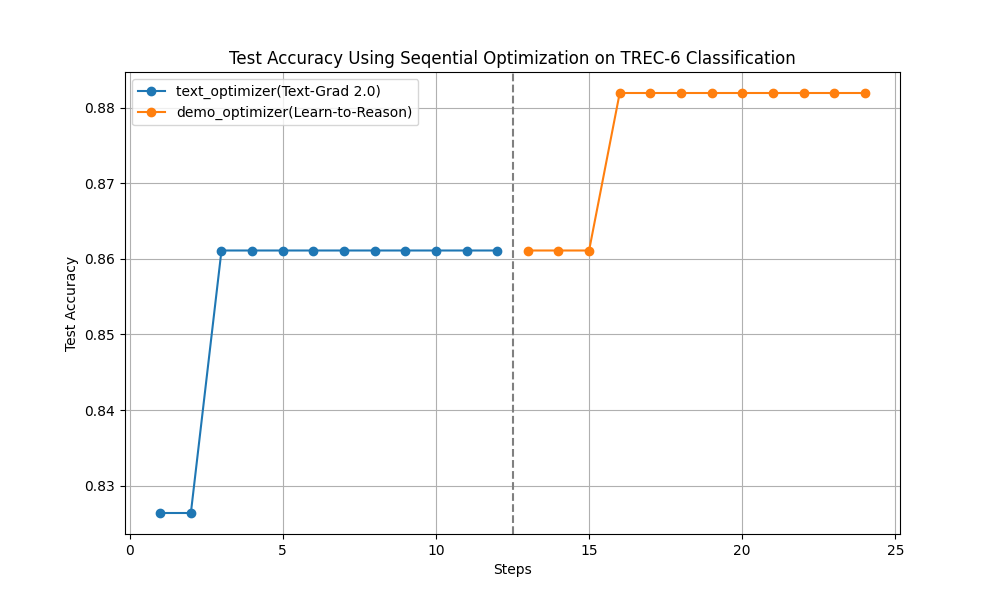
Learning Curve on training system task instruction and on one-shot demonstration.¶

The optimized prompt for the classification task.¶
Here is what you will learn from this tutorial:
How to build a classification task pipeline with structured output.
The concepts of
mixedandsequentialtraining as we explore bothTextOptimizerandDemoOptimizerto optimize the classification task.How to handle the situations where the val dataset is not a good indicator of test accuracy.
Note
You can find all our code in our GitHub repo: use_cases/classification, and the Dspy implementation at benchmarks/trec_classification.
Task Pipeline with Structured Output¶
We will use the following overall template with system_prompt, output_format_str, and few_shot_demos varaibles.
task_desc_template will be used to render the final classification task description from class names and each label’s description.
TRECExtendedData is a dataclass that extends TrecData with a rationale field. This will ensure our generator to first levarage ‘Chain-of-Thought’ reasoning before predicting the final class_name.
template = r"""<START_OF_SYSTEM_MESSAGE>
{{system_prompt}}
{% if output_format_str is not none %}
{{output_format_str}}
{% endif %}
{% if few_shot_demos is not none %}
Here are some examples:
{{few_shot_demos}}
{% endif %}
<END_OF_SYSTEM_MESSAGE>
<START_OF_USER_MESSAGE>
{{input_str}}
<END_OF_USER_MESSAGE>
"""
task_desc_template = r"""You are a classifier. Given a question, you need to classify it into one of the following classes:
Format: class_index. class_name, class_description
{% if classes %}
{% for class in classes %}
{{loop.index-1}}. {{class.label}}, {{class.desc}}
{% endfor %}
{% endif %}
- Do not try to answer the question:
"""
@dataclass
class TRECExtendedData(TrecData):
rationale: str = field(
metadata={
"desc": "Your step-by-step reasoning to classify the question to class_name"
},
default=None,
)
__input_fields__ = ["question"]
__output_fields__ = ["rationale", "class_name"] # it is important to have the rationale before the class_name
We will subclass from Component for our final task pipeline.
We use DataClassParser to streamline the process of output formatting and parsing.
class TRECClassifierStructuredOutput(adal.Component):
def __init__(self, model_client: adal.ModelClient, model_kwargs: Dict):
super().__init__()
label_desc = [
{"label": label, "desc": desc}
for label, desc in zip(_COARSE_LABELS, _COARSE_LABELS_DESC)
]
task_desc_str = adal.Prompt(
template=task_desc_template, prompt_kwargs={"classes": label_desc}
)()
self.data_class = TRECExtendedData
self.data_class.set_task_desc(task_desc_str)
self.parser = adal.DataClassParser(
data_class=self.data_class, return_data_class=True, format_type="yaml"
)
prompt_kwargs = {
"system_prompt": adal.Parameter(
data=self.parser.get_task_desc_str(),
role_desc="Task description",
requires_opt=True,
param_type=adal.ParameterType.PROMPT,
),
"output_format_str": adal.Parameter(
data=self.parser.get_output_format_str(),
role_desc="Output format requirements",
requires_opt=False,
param_type=adal.ParameterType.PROMPT,
),
"few_shot_demos": adal.Parameter(
data=None,
requires_opt=True,
role_desc="Few shot examples to help the model",
param_type=adal.ParameterType.DEMOS,
),
}
self.llm = adal.Generator(
model_client=model_client,
model_kwargs=model_kwargs,
prompt_kwargs=prompt_kwargs,
template=template,
output_processors=self.parser,
use_cache=True,
)
def _prepare_input(self, question: str):
input_data = self.data_class(question=question)
input_str = self.parser.get_input_str(input_data)
prompt_kwargs = {
"input_str": adal.Parameter(
data=input_str, requires_opt=False, role_desc="input to the LLM"
)
}
return prompt_kwargs
def call(
self, question: str, id: Optional[str] = None
) -> Union[adal.GeneratorOutput, adal.Parameter]:
prompt_kwargs = self._prepare_input(question)
output = self.llm(prompt_kwargs=prompt_kwargs, id=id)
return output
In this taske pipeline, we have prepared two trainable prameters: system_prompt and few_shot_demos and each is of type adal.ParameterType.PROMPT and adal.ParameterType.DEMOS respectively.
We will need TGDOptimizer to optimize system_prompt and BootstrapOptimizer
to optimize few_shot_demos.
Define the AdalComponent¶
Now, we will define a subclass of AdalComponent to prepare the pipeline for training.
We have set up the eval_fn, loss_fn, along with methods to configure backward engine for the text optimizer,
as well as a method method to configure teacher generator for the demo optimizer.
class TrecClassifierAdal(adal.AdalComponent):
def __init__(
self,
model_client: adal.ModelClient,
model_kwargs: Dict,
teacher_model_config: Dict,
backward_engine_model_config: Dict,
text_optimizer_model_config: Dict,
):
task = TRECClassifierStructuredOutput(model_client, model_kwargs)
eval_fn = AnswerMatchAcc(type="exact_match").compute_single_item
loss_fn = adal.EvalFnToTextLoss(
eval_fn=eval_fn,
eval_fn_desc="exact_match: 1 if str(y) == str(y_gt) else 0",
)
super().__init__(
task=task,
eval_fn=eval_fn,
loss_fn=loss_fn,
backward_engine_model_config=backward_engine_model_config,
text_optimizer_model_config=text_optimizer_model_config,
teacher_model_config=teacher_model_config,
)
def prepare_task(self, sample: TRECExtendedData):
return self.task.call, {"question": sample.question, "id": sample.id}
def prepare_eval(
self, sample: TRECExtendedData, y_pred: adal.GeneratorOutput
) -> float:
y_label = -1
if y_pred and y_pred.data is not None and y_pred.data.class_name is not None:
y_label = y_pred.data.class_name
return self.eval_fn, {"y": y_label, "y_gt": sample.class_name}
def prepare_loss(
self, sample: TRECExtendedData, y_pred: adal.Parameter, *args, **kwargs
) -> Tuple[Callable[..., Any], Dict]:
full_response = y_pred.full_response
y_label = -1
if (
full_response
and full_response.data is not None
and full_response.data.class_name is not None
):
y_label = full_response.data.class_name
y_pred.eval_input = y_label
y_gt = adal.Parameter(
name="y_gt",
data=sample.class_name,
eval_input=sample.class_name,
requires_opt=False,
)
return self.loss_fn, {"kwargs": {"y": y_pred, "y_gt": y_gt}}
Trainer and Training Strategy¶
Training Strategy
The following code shows our default training configuration. We use a batch size of 4, 12 steps, and 4 workers to call LLMs in parallel.
The optimize_order is set to sequential to first train the text optimizer and then the demo optimizer.
This training strategy has been working well. With the text optimized, this might boost the performance for the teacher model.
With the teacher model’s reasoning, the demo optimizer can learn to reason better even with merefly one demonstration from the teacher.
When we are at the sequential optimization order, we will end up with 24 steps trained.
In addition, you can try mixed for the optimization order, where at each step, it will update both the text optimizer and the demo optimizer.
def train(
model_client: adal.ModelClient,
model_kwargs: Dict,
train_batch_size=4, # larger batch size is not that effective, probably because of llm's lost in the middle
raw_shots: int = 0,
bootstrap_shots: int = 1,
max_steps=12,
num_workers=4,
strategy="constrained",
optimization_order="sequential",
debug=False,
):
# TODO: ensure the teacher prompt gets updated with the new model
adal_component = TrecClassifierAdal(
model_client=model_client,
model_kwargs=model_kwargs,
text_optimizer_model_config=gpt_4o_model,
backward_engine_model_config=gpt_4o_model,
teacher_model_config=gpt_4o_model,
)
print(adal_component)
trainer = adal.Trainer(
train_batch_size=train_batch_size,
adaltask=adal_component,
strategy=strategy,
max_steps=max_steps,
num_workers=num_workers,
raw_shots=raw_shots,
bootstrap_shots=bootstrap_shots,
debug=debug,
weighted_sampling=True,
optimization_order=optimization_order,
exclude_input_fields_from_bootstrap_demos=True,
)
print(trainer)
train_dataset, val_dataset, test_dataset = load_datasets()
trainer.fit(
train_dataset=train_dataset,
val_dataset=test_dataset,
debug=debug,
)
In this case, we did not use val_dataset as we did diagnose and as shown in Table 1, the val dataset is not a good indicator for the test accuracy.
Thus, our final training strategy is to directly validate on the test dataset.
Training checkpoints:
At the end of the training, we will print out the ckpt path where you can look up all the details about the trained prompt. Here is our above training:
Loading Data: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 144/144 [00:00<00:00, 51011.81it/s]
Evaluating step(24): 0.8426 across 108 samples, Max potential: 0.8819: 75%|█████████████████████████████████████████████████████████████████████▊ | 108/144 [00:00<00:00, 1855.48it/s]
Fail validation: 0.8348623853211009 <= 0.8819444444444444, revert
Training Step: 24: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12/12 [03:05<00:00, 15.46s/it]
Saved ckpt to /Users/liyin/.adalflow/ckpt/TrecClassifierAdal/constrained_max_steps_12_848d2_run_7.json
Training time: 823.8977522850037s
We can see that the training takes only 14 minutes. We use 12 steps, and the learning curve is shown in Fig 1. Here is our trained system prompt and the demo prompt:
system_prompt = "You are a classifier. Given a question, you need to classify it into one of the following classes:\nFormat: class_index. class_name, class_description\n0. ABBR, Abbreviation or acronym\n1. ENTY, Entity, including specific terms, brand names, or other distinct entities\n2. DESC, Description and abstract concept, including explanations, characteristics, and meanings\n3. HUM, Human being\n4. LOC, Location, including spatial information, geographical places\n5. NUM, Numeric value, including measurable figures, quantities, distances, and time\n- Focus on correctly identifying the class based on the question's main inquiry:"
few_shot_demos = "rationale: The question is asking for a specific term used to describe the sum of\n all genetic material in an organism.\nclass_name: ENTY"
We can see that compared with our initial prompt, it adds some concise explanation to each class. The demo prompt is also short, directly from a teacher model teaching the student model to do rationale to reach to the final class_name.
Performance & Benchmark¶
We implemented Dspy Boostrap few-shot with random search.
Here is the DsPy’s Signature (similar to the prompt) where its task description is a direct copy our AdalFlow’s starting prompt:
class GenerateAnswer(dspy.Signature):
"""You are a classifier. Given a question, you need to classify it into one of the following classes:
Format: class_index. class_name, class_description
1. ABBR, Abbreviation
2. ENTY, Entity
3. DESC, Description and abstract concept
4. HUM, Human being
5. LOC, Location
6. NUM, Numeric value
- Do not try to answer the question:"""
question: str = dspy.InputField(desc="Question to be classified")
answer: str = dspy.OutputField(
desc="Select one from ABBR, ENTY, DESC, HUM, LOC, NUM"
)
Here is the performance result
Method |
Train |
Val |
Test |
|---|---|---|---|
Start (manual prompt) |
67.5% (20*6 samples) |
69.4% (6*6 samples) |
82.64% (144 samples) |
Start (GPT-4o/Teacher) |
77.5% |
77.78% |
86.11% |
DsPy (Start) |
57.5% |
61.1% |
60.42% |
DsPy (bootstrap 4-shots + raw 36-shots) |
N/A |
86.1% |
82.6% |
AdalFlow (Optimized Zero-shot) |
N/A |
77.78%, 80.5% (+8.4%) |
86.81%, 89.6% (+4.2%) |
AdalFlow (Optimized Zero-shot + bootstrap 1-shot) |
N/A |
N/A |
88.19% |
AdalFlow (Optimized Zero-shot + bootstrap 1-shot + 40 raw shots) |
N/A |
86.1% |
90.28% |
AdalFlow (Optimized Zero-shot on GPT-4o) |
77.8% |
77.78% |
84.03% |
In this case, our text optimizer–Text-Grad 2.0 is able to close the gap to the teacher model, leaving little space for the DemoOptimizer to improve as it learns to boost its reasoning from a teacher model’s reasoning. Even though the many-shots (as many as 40) can still improve the performance for a bit, but it will adds a lot more tokens.
We can see that being able to flexibly control the prompt instead of delegate to a fixed Signature is advantageous.
We use yaml format for the output in this case, and be able to use template to control which part we want to train.
We trained to train a joined Parameter with both the system prompt and the output format, and found it is more effecitive to just train the system prompt.
Conclusion:
Our SOTA performance is due to the combination of
Our research on optimizers: Each individual optimizer, the text optimizer implementing our research Text-grad 2.0 and the demo optimizer implementing our research
Learn-to-reason Few-shot In-context LearningOur research on training paradigm: The sequential training where we first train the text optimizer and then train the demo optimizer is proven to be effective to optimize the performe without adding too many tokens in the prompt.
The flexibility and customizability of the library: With the library to provide developers direct control over the prompt and allow flexible and granular definition of the parameters is the second of the reason that we can surpass other methods by a large margin.