Developer Notes¶
Learn the why and how-to (customize and integrate) behind each core part within the AdalFlow library. These are our most important tutorials before you move ahead to build your use cases end to end.
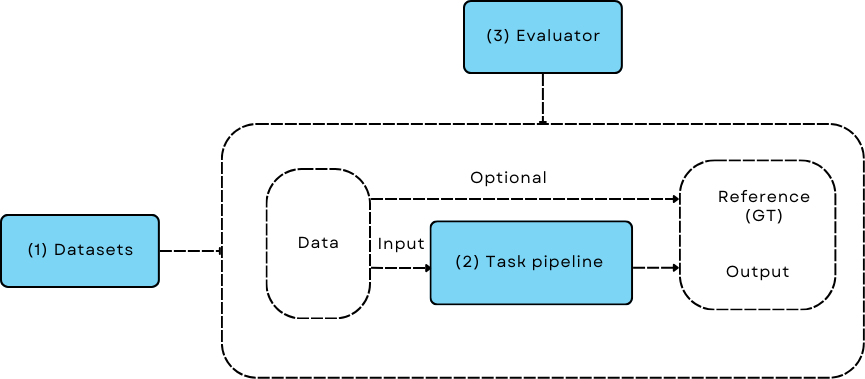
LLM application is no different from a mode training/evaluation workflow¶
The AdalFlow library focuses on providing building blocks for developers to build and optimize the task pipeline. We have a clear Design Philosophy, which results in this Class Hierarchy.
Introduction¶
Component is to LLM task pipelines what nn.Module is to PyTorch models. An LLM task pipeline in AdalFlow mainly consists of components, such as a Prompt, ModelClient, Generator, Retriever, Agent, or any other custom components. This pipeline can be Sequential or a Directed Acyclic Graph (DAG) of components. A Prompt will work with DataClass to ease data interaction with the LLM model. A Retriever will work with databases to retrieve context and overcome the hallucination and knowledge limitations of LLM, following the paradigm of Retrieval-Augmented Generation (RAG). An Agent will work with tools and an LLM planner for enhanced ability to reason, plan, and act on real-world tasks.
Additionally, what shines in AdalFlow is that all orchestrator components, like Retriever, Embedder, Generator, and Agent, are model-agnostic. You can easily make each component work with different models from different providers by switching out the ModelClient and its model_kwargs.
We will introduce the library starting from the core base classes, then move to the RAG essentials, and finally to the agent essentials. With these building blocks, we will further introduce optimizing, where the optimizer uses building blocks such as Generator for auto-prompting and retriever for dynamic few-shot in-context learning (ICL).
Building¶
Base classes¶
Code path: adalflow.core.
Base Class |
Description |
|---|---|
The building block for task pipeline. It standardizes the interface of all components with call, acall, and __call__ methods, handles state serialization, nested components, and parameters for optimization. Components can be easily chained together via |
|
The base class for data. It eases the data interaction with LLMs for both prompt formatting and output parsing. |
RAG Essentials¶
RAG components¶
Code path: adalflow.core. For abstract classes:
ModelClient: the functional subclass is in adalflow.components.model_client.Retriever: the functional subclass is in adalflow.components.retriever.
Part |
Description |
|---|---|
Built on jinja2, it programmatically and flexibly formats prompts as input to the generator. |
|
The standard protocol to intergrate LLMs, Embedding models, ranking models, etc into respective orchestrator components, either via APIs or local to reach to model agnostic. |
|
The orchestrator for LLM prediction. It streamlines three components: ModelClient, Prompt, and output_processors and works with optimizer for prompt optimization. |
|
The interpreter of the LLM output. The component that parses the output string to structured data. |
|
The component that orchestrates model client (Embedding models in particular) and output processors. |
|
The base class for all retrievers, which in particular retrieve relevant documents from a given database to add context to the generator. |
Data Pipeline and Storage¶
Data Processing: including transformer, pipeline, and storage. Code path: adalflow.components.data_process, adalflow.core.db, and adalflow.database.
Components work on a sequence of Document and return a sequence of Document.
Part |
Description |
|---|---|
To split long text into smaller chunks to fit into the token limits of embedder and generator or to ensure more relevant context while being used in RAG. |
|
Understanding the data modeling, processing, and storage as a whole. We will build a chatbot with enhanced memory and memoy retrieval in this note (RAG). |
Putting it all together¶
Part |
Description |
|---|---|
Comprehensive RAG playbook according to the sota research and the best practices in the industry. |
|
Building RAG systems with conversation memory for enhanced context retention and follow-up handling. |
Agent Essentials¶
Agent in components.agent is LLM great with reasoning, planning, and using tools to interact and accomplish tasks.
Part |
Description |
|---|---|
Provide tools (function calls) to interact with the generator. |
|
The ReactAgent. |
Advanced Topics¶
Optimization¶
AdalFlow auto-optimization provides a powerful and unified framework to optimize every single part of the prompt: (1) instruction, (2) few-shot examples, and (3) the prompt template, for any task pipeline you have just built. We leverage all SOTA prompt optimization from Dspy, Text-grad, ORPO, to our own research in the library.
The optimization requires users to have at least one dataset, an evaluator, and define optimizor to use. This section we will briefly cover the datasets and evaluation metrics supported in the library.
Evaluation¶
You can not optimize what you can not meature. In this section, we provide a general guide to the evaluation datasets, metrics, and methods to productionize your LLM tasks and to publish your research.
Part |
Description |
|---|---|
A quick guide to the evaluation datasets, metrics, and methods. |
|
How to load and use the datasets in the library. |
Training¶
Code path: adalflow.optim.
Adalflow defines four important classes for auto-optimization: (1) Parameter, similar to role of nn.Tensor in PyTorch,
(2) Optimizer wh, (3) AdalComponent to define the training and validation steps, and (4) Trainer to run the training and validation steps on either data loaders or datasets.
We will first introduce these classes, from their design to important features each class provides.
Classes¶
Note: Documentation is work in progress for this section.
Part |
Description |
|---|---|
parameter_ |
The Parameter class stores the text, textual gradidents(feedback), and managed the states and applies the backpropagation in auto-diff. |
optimizer_ |
The Optimizer to define a structure and to manage propose, revert, and step methods. We defined two variants: DemoOptimizer and TextOptimizer to cover the prompt optimization and the few-shot optimization. |
few_shot_optimizer_ |
Subclassed from |
auto_text_grad_ |
Subclassed from |
adalcomponent_ |
The |
trainer_ |
The |
Logging & Tracing¶
Code path: adalflow.utils and adalflow.tracing.
Part |
Description |
|---|---|
AdalFlow uses native |
|
We provide two tracing methods to help you develop and improve the Generator: 1. Trace the history change(states) on prompt during your development process. 2. Trace all failed LLM predictions in a unified file for further improvement. |