
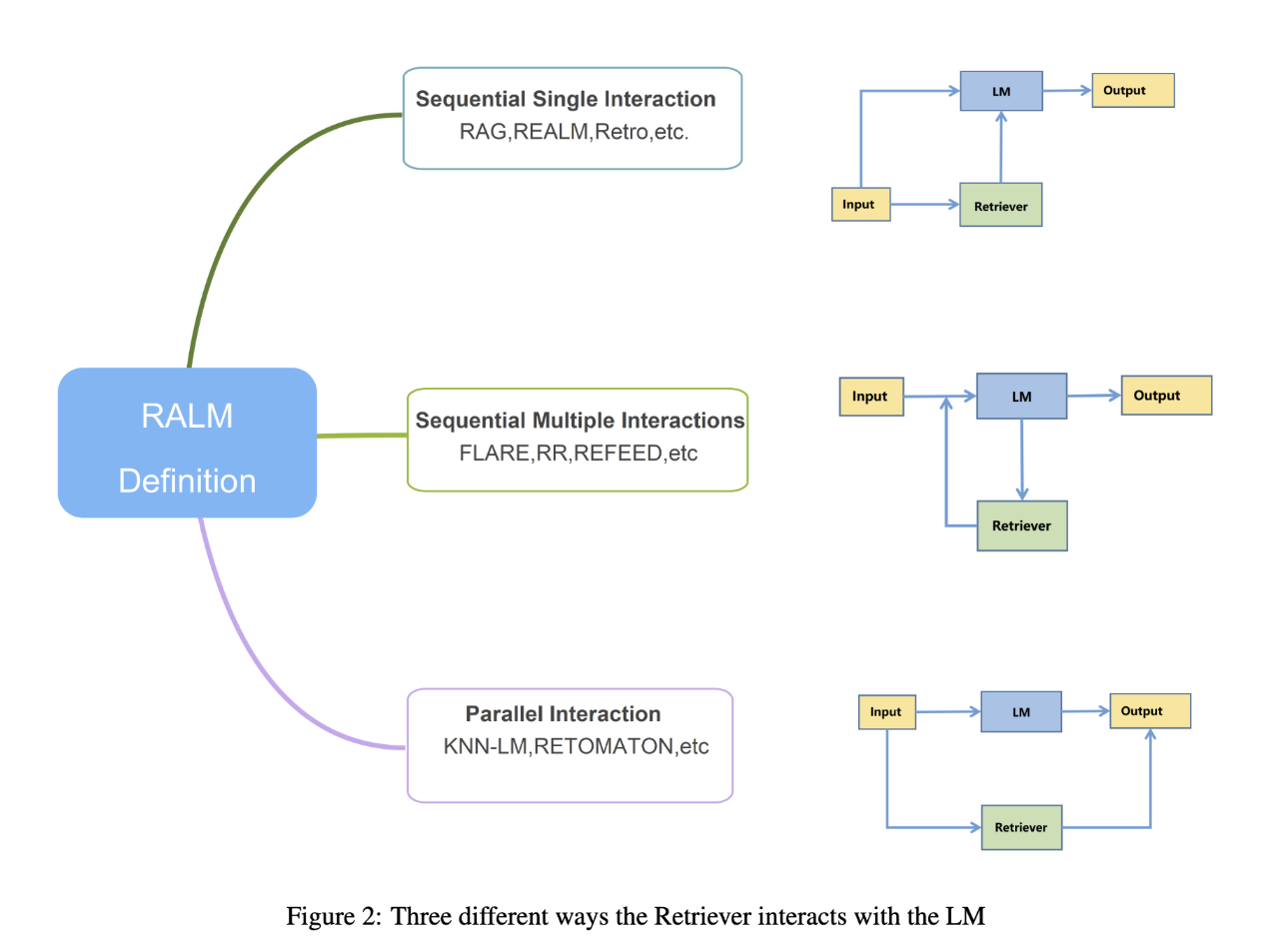
RAG Playbook¶
Note
This tutorial is still a work in progress. We will continue updating and improving it. If you have any feedback, feel free to reach out to us in any of the following ways: Community.
In this playbook, we will provide a comprehensive RAG playbook according the sota research and the best practices in the industry. The outline of the playbook is as follows:
RAG Overview
From First RAG Paper to the diverse RAG design architecture
RAG design and tuning strategies for each component
RAG Overview¶
Retrieval-Augmented Generation (RAG) is a paradigm that combines the strengths of retrieval to eliminate hallucination, knowledge cut-off problem of LLMs, and as a way to adapt to any doman-specific knowledge base. Moreover, being able to cite the source of knowledge is a big plus for the transparency and interpretability of any AI use case.
RAG_PROMPT_TEMPLATE = r"""<START_OF_SYSTEM_MESSAGE>
{{task_desc}}
<END_OF_SYSTEM_MESSAGE>
<START_OF_USER>
{{input_str}}
{{context_str}}
<END_OF_USER>
"""
Given a user query, RAG retrieves relevant passages from a large corpus and then generates a response based on the retrieved passages. This formulation opens up a wide range of use cases such as conversational search engine, question answering on a customized knowledge base, customer support, fact-checking. The template above shows the most commonly used format of RAG, where we pass a task description, concatenate the input string, and retrieve passages into a context string, which is then passed to an LLM model for generation.
But, RAG is way more than that. Let’s dive in.
First RAG Papers
RAG was introduced in 2020 by Lewis et al. from Meta [1] which is an architecture that finetunes both the query encoder (bi-encoder like most embedding models) and the generator (LLM) jointly with only final answer supervision.
REALM [7] is another RAG model introduced the same year by Google not only finetunes both the retriever and the generator on the downstream tasks but also pretrained these two models jointly by randomly masking tokens in a simpled piece of text using masked langage model (MLM).
The intial papers did not mention document chunking as most of the time, their text length is usally short and also fits into the context length of the embedding models. As both the embedding model and LLM model scales up in terms of knowledge and parameters (400M LLM model used in the paper), RAG can achieve high performance in few-shot (prompt engineering) setup without the finetune.
However, the flexibility of the RAG also means that it requires careful design and tuning to achieve optimal performance. For each use case, we need to consider the following questions:
What retrieval to use? And how many stages it should be? Do we need a reranker or even LLM to help with the retrieval stages?
Which cloud-database can go well with the retrieval strategy and be able to scale?
How do I evaluate the performance of the RAG as a whole? And what metrics can help me understand the retrieval stage in particular so that I know it is not hurting the overall performance?
Do I need query expansion or any other techniques to improve the retrieval performance? How to avoid the performance degradation due to feeding the LLM irrelevant passages?
How do I optimize the RAG hyperparameters such as the number of retrieved passages, the size of the chunk, and the overlap between chunks, or even the chunking strategy?
Sometimes you need to even create your own customized/finetuned embedding/retriever models. How do I do that?
How do I auto-optimize the RAG pipeline with In-context learning(ICLs) with zero-shot prompting and few-shot prompting?
What about finetuning? How to do it and would it be more token efficient or more effective?
Designing RAG¶
RAG Component |
Techniques |
Metrics |
|---|---|---|
Data Preparation |
|
|
Data Storage |
|
|
Embedding |
|
|
Indexing |
||
Retrieval |
|
|
Generator |
|
|
TODO: make this a table that i can put in links. so that i can link together other tutorials to form a comprehensive playbook.
For benchmarking datasets and metrics, please refer to Evaluation Guideline. Additionally, FlashRAG [3] provides more references to RAG datasets and research.
Data Preparation Pipeline¶
Document Retrieval & Reranking¶
Multi-stage retrieval from the cheapest, fastest, and least accurate to the most expensive, slowest, and most accurate is introduced in Retriever.
RAG optimization¶
We can either optimize each component separately such as retriever or the generator drawing research that was designed for each, or optimize them jointly in the context of RAG. Sometimes we can use an agentic approach, such as Self-RAG [11].
#TODO: fit hydro
Retrieval Optimization
As irrelevant passages, especially those positioned on top of the context can degrade the final performance, it is important to optimize the retrieval performance in particular: We have the following options:
Hyperparmeters optimization: optimize the number of retrieved passages, the size of the chunk, and the overlap between chunks, or even the chunking strategy using retriever evaluation metrics or the final generator performance.
Query expansion: improve the recall by expanding the query.
Adapt the embedder with LLM supervision: adapt the embedder with LLM supervision to improve the retrieval recall and precision.
Reranking: use a reranker as an additional stage to improve the retrieval accuracy.
Use Retrieval Evaluator: use a retrieval evaluator to evaluate the relevance of the retrieved passages.
Generator Optimization
Ever since the first RAG papers, many LLMs with high parameters count and performance have been released. In-context learning (ICL) or prompt engineering has become the first choice over model finetuning to optimize the generator’s performance on any task. You can use any optimization methods designed to improve the reasoning ability of the generator, such as chain-of-thought, reflection, etc.
When Generator is used in the context of RAG, however, we need to consider the relation between (retrieved context, query, and generated response). And we need to optimize the generator on:
How well can it use the relevant context to generate the response? Was it mislead by irrelevant passages?
For generator, we have three popular options:
Prompt-engineering: use zero-shot or few-shot learning to optimize the generator, or improve the generator response via more test-time tokens (e.g., chain-of-thought, reflection).
Finetune the generator with instruction learning
Finetune the generator in particular with the format of using context.
In the future, we will provide a prompt engineering/ICL playbook and we will skip this part for now.
Retrieval optimization¶
Query Transformation
Query Expansion (QE) [16] is a common technique used in search engine to expand the user’s search query to include additional documents.
In this new age of LLM, query can be rewritten/expanded via LLM.
Query Rewriting
By prompt-engineering the LLM to rewrite the initial query \(x\) to \(x' = LLM(Prompt(x))\), we end up optimize the retriever performance without retraining the retriever as the paper Lewis et al. [1] did. By leveraging AdalFlow’s in-context trainer, we can auto-optimize the RAG pipeline end to end. The only downside is to use more token bugets of the LLM model which will end up to be more expensive.
Here we summarize a few methods and introduce AdalFlow’s API.
Query Rewriting paper [17] propose two ways to do the rewriting with LLM:
Few-shot prompt: to encourage the LLM to “reason” and output none, one or multiple queries that are relevant to the input query.
Trainable scheme: Use a smaller rewriter model to rewrite the query instead of a black-box LLM, to reduce the cost.
The rewritter is trained using the feedback of the generator by reinforcement learning. It has two stages of training: warm-up where a synthetic dataset of \((x, x')\) pairs which has led to correct generator response is used to finetune the rewriter. Then, the rewriter is trained with reinforcement learning to align to the retriever and the genearator.
Adapt the embedder with LLM supervision
To improve the retrieval recall and precision, we can adapt the embedder with LLM supervision. The cheapest solutions requires only a linear layer on top of the embedding model along with a synthesized dataset of query-passage pairs generated from the data source using LLM models. This approach also applys to black-box embedding models. AdalFlow will consider to open-source this technique in the future.
A second approach is to finetune the embedder directly. Replug [6] is a good example of this approach. Replug can be used with or without finetune.
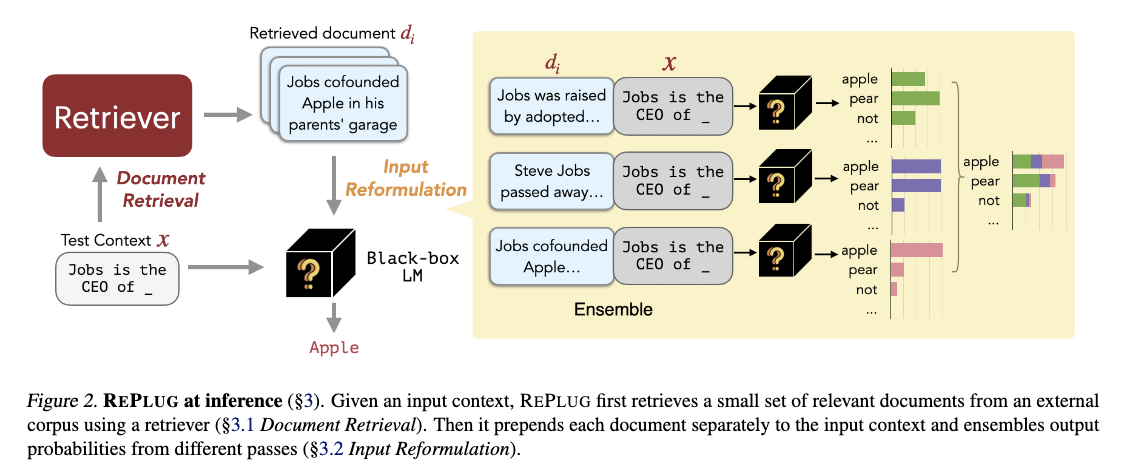
When we do Replug, it computes the LLM output of each query and document pair separately in parallel and ensembles all the outputs to get the final score. This is especially helpful for inference speed and surpass the context length limitation of the LLM model.
Reranking
Rerankers are often cross-encoder between the query and documents. It is computationally more expensive but also more accurate. Cohere and Transformers both offer sota rerankers.
Use Retrieval Evaluator
C-RAG [10] proposed a lightweight retrieval evaluator that was finetuned on the training split of the testing datasets. More expensively, but without the need to train a model, we can use LLM to classify the relevance of the retrieved passages, using labels such as “correct”, “incorrect”, “ambiguous”, etc.
Generator optimization¶
Besides of the three popular options mentioned above, there is a branch of research where the retrieved context is combined in the generator (enhanced generator) as a part of the model to integrate the context instead of simply combining it from the prompt.
RAG pipeline optimization¶
We introduce three popular overall optimization strategies for the RAG pipeline.
Self-RAG¶
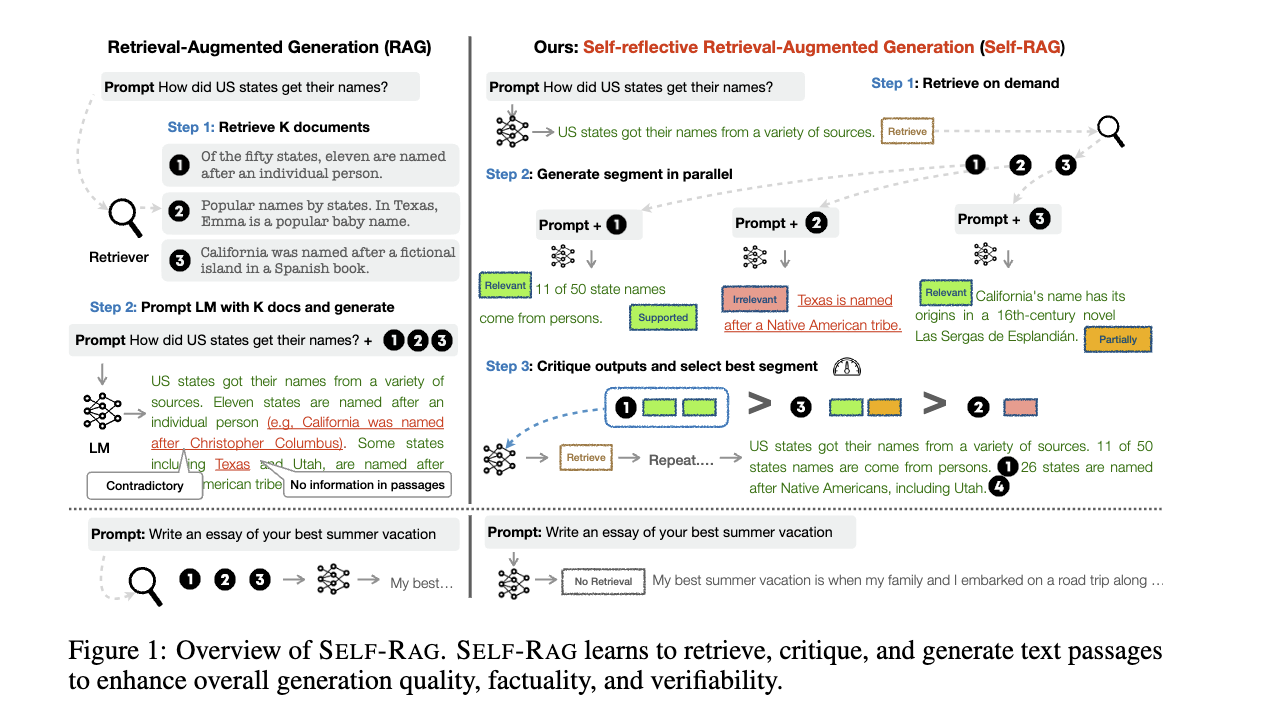
Self-RAG is interesting as it is programmed to decide if retrieval is needed, it handles the retrieved passages separately in parallel to generate y_t for each query x and passage d_t. For each (x, d_t, y_t) pair it “reflects” on three metrics:
ISREL: use (x, d_t) to check if d_t provides useful information to solve x by outputing two labels (is_relevant, is_irrelevant).
ISSUP: use (x, d_t, y_t) to check if all of the worthy statements(answers the question) in y_t is supported by d_t by outputing three labels (is_supported, partically_supported, not_supported).
ISUSE: use (x, y_t) to check if y_t is useful to solve x by outputing 5 labels (5, 4, 3, 2, 1).
It computes a single segment score unifying the three metrics and uses it to rerank the answer and pick the answer with the highest score as the final answer. The paper also mentioned how to create synthesized training dataset and train the critic and generator model. Good thing is Self-RAG can be used with or without finetune.
Self-RAG can be applied on complicated tasks that require high accuracy, but it is way more complicated than a vanila RAG.
REALM¶
REALM [7] is quite interesting and it has a clear optimization objective.
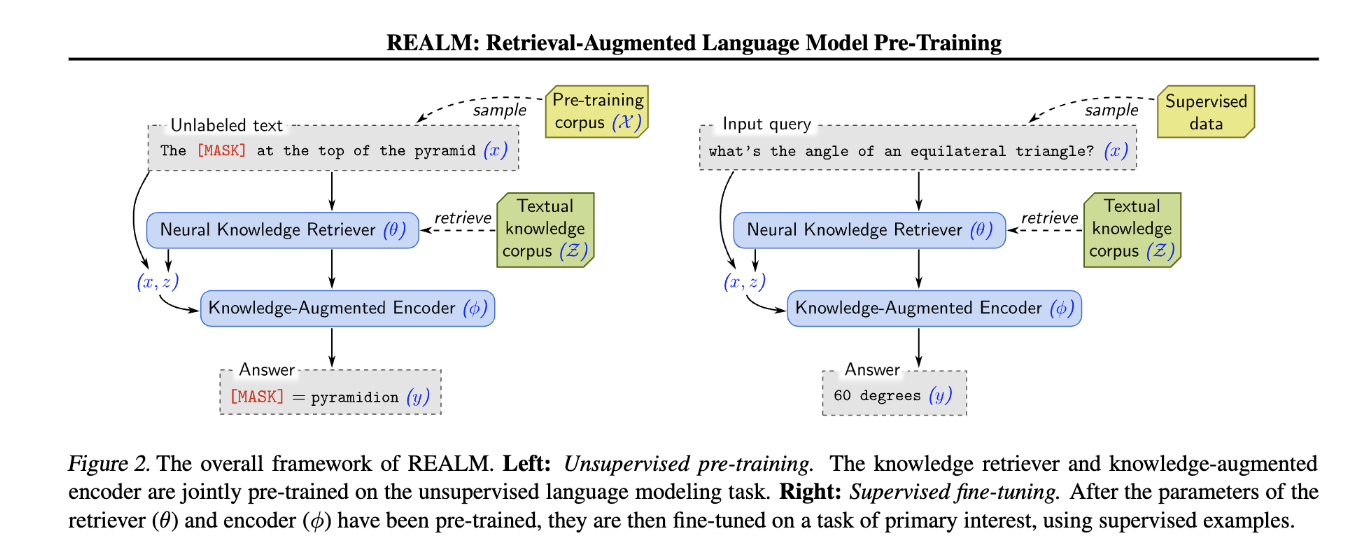
Retrieve-Then-Predict Process
REALM models the task as a “retrieve-then-predict” process:
First, the retriever samples documents \(z\) from a large knowledge corpus \(Z\) based on the input \(x\). This retrieval is modeled by \(p(z | x)\), the probability of retrieving document \(z\) given input \(x\).
Then, the model predicts the missing words or answers based on both the input \(x\) and the retrieved document \(z\), modeled as \(p(y | z, x)\), where \(y\) is the prediction (e.g., masked tokens or answers).
Marginalizing Over All Possible Documents
The probability of correctly predicting the target output \(y\) given input \(x\) is computed by marginalizing over all possible documents in the knowledge corpus \(Z\):
This means that the overall probability is a weighted sum of how well each document \(z\) helps predict \(y\), weighted by the retriever’s belief \(p(z | x)\) in that document.
Loss Function and Gradient Optimization
The key to optimizing the retriever is to maximize the likelihood of the correct prediction \(y\) by adjusting the probability \(p(z | x)\) of retrieving relevant documents. The log-likelihood of the correct prediction \(y\) is the training objective:
Rewarding Relevant Documents
To see how the retriever is rewarded or punished, consider the gradient of the log-likelihood with respect to the retriever’s scoring function \(f(x, z)\) (which measures how relevant document \(z\) is to input \(x\)):
Here’s how this works:
If the document \(z\) improves the prediction of \(y\) (i.e., \(p(y | z, x) > p(y | x)\)), the gradient is positive, and the retriever is encouraged to increase the score \(f(x, z)\), making it more likely to retrieve that document in the future.
If the document \(z\) does not help (i.e., \(p(y | z, x) < p(y | x)\)), the gradient is negative, and the retriever is encouraged to decrease the score \(f(x, z)\), making it less likely to retrieve that document.