Retriever¶
LLMs halluciate and also have a knowledge cut-off.
External and relevant context is needed to increase the factuality, relevancy, and freshness of the LLM answers.
Due to the LLM’s context window limit (it can only take so many tokens at a time), the lost-in-the-middle problem [6], and the high cost in speed and resources using large context,
it is practical to use a retriever to retrieve the most relevant information for the best performance. Retrieval Augemented Generation (RAG) [7] applications have become one of main applications in LLMs.
What is a retriever?
Though the definition is simple-“Retrieve relevant information for a given query from a given database”-the scope of a retriever can extend as wide as the entire search and information retrieval field. Numerous search techniques existed long before vector/semantic search and reranking models, such as keyword search, fuzzy search, proximity search, phrase search, boolean search, facet search, full-text search. These techniques can be applied to various data types, including text, time-sensitive data, locations, sensor data, images, videos, and audio. Additionally, they can be stored in various types of databases, such as relational databases, NoSQL databases, vector databases, and graph databases.
Retrieval in Production
In real production, retrieval is often a multiple-stage process, progressing from the cheapest to the most expensive and accurate methods, narrowing down from millions of candidates to a few hundred or even less. For example, when you want to search for candidates from a pool of profiles stored in a realtional database like Postgres, you can start with a simple keyword search or check if the name equals the query. You may also want to search by profession, which has already been categorized either by a model or human labeling, making it a filter search. If the search query requires more semantic understanding, we will leverage semantic search using embedding models. If we want it to be even more accurate, we can move up to more expensive and accurate methods such as reranking models and LLM-based retrieval methods.
Design¶
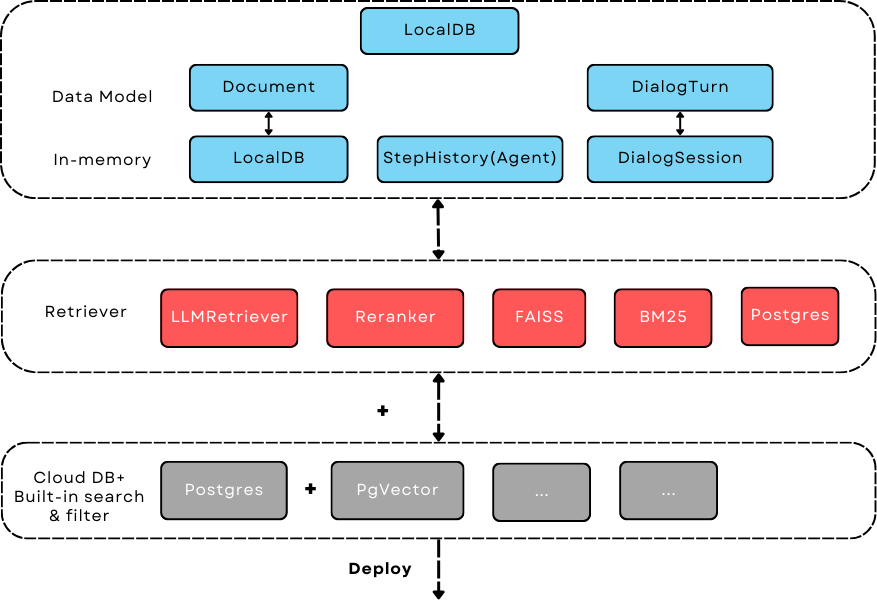
AdalFlow retriever covers (1) high-precision retrieval methods and enables them to work locally and in-memory, and (2) how to work with cloud databases for large-scale data, utilizing their built-in search and filter methods.¶
Scope and Design Goals¶
AdalFlow library does not prioritize the coverage of integration for the following reasons:
It is literally too-wide to cover them all.
The challenges with RAG application lies more in evaluation and optimization due to many different moving parts and many hyperparmeters, and less in implementing or integrating a 3rd party retriever.
Instead, our design goals are:
Cover representative and valuable retriever methods:
High-precision retrieval methods and enabling them to work locally and in-memory so that researchers and developers can build and test more efficiently.
Showcase how to work with cloud databases for large-scale data, utilizing their built-in search and filter methods.
Provide a clear design pattern so that users can:
Easily integrate their own retriever and make it work seamlessly with the remaining part of the LLM task pipeline.
Easily combine different retriever methods to form a multiple-stage retrieval pipeline.
Here are current coverage on retriever methods:
LLMAsRetriever
Reranker (Cross-encoder)
Semantic Search (Bi-encoder)
BM25
Database’s built-in search such as full-text search/SQL-based search using Postgres and semantic search using
PgVector.
With Database¶
A retriever will work hand in hand with database.
We will provide a LocalDB and a cloud SQL-based database (using SQLAlchemy) that can work with any data class/model, espeically with the Document for data processing and DialogTurn for conversational data.
Document combined with text splitter and embedding models will provide the context in RAG.
Working with DialogTurn can help manage conversation_history, especiall for the lifelong memeory of a chatbot.
Retriever Data Types¶
Query
In most cases, the query is string. But there are cases where we might need both text and images as a query, such as “find me a cloth that looks like this”. We defined the query type RetrieverQueriesType so that all of our retrievers should handle both single query and multiple queries at once. For text-based retrievers, we defined RetrieverStrQueriesType as a string or a sequence of strings.
RetrieverQueryType = TypeVar("RetrieverQueryType", contravariant=True)
RetrieverStrQueryType = str
RetrieverQueriesType = Union[RetrieverQueryType, Sequence[RetrieverQueryType]]
RetrieverStrQueriesType = Union[str, Sequence[RetrieverStrQueryType]]
Documents
The documents are a sequence of documents of any type, which will be later specified by the subclass:
RetrieverDocumentType = TypeVar("RetrieverDocumentType", contravariant=True) # a single document
RetrieverDocumentsType = Sequence[RetrieverDocumentType] # The final documents types retriever can use
Output
We further definied the unified output data structure RetrieverOutput so that we can easily switch between different retrievers in our task pipeline.
A retriever should return a list of RetrieverOutput to support multiple queries at once. This is helpful for:
Batch-processing: Especially for semantic search, where multiple queries can be represented as numpy array and computed all at once, providing faster speeds than processing each query one by one.
Query expansion: To increase recall, users often generate multiple queries from the original query.
@dataclass
class RetrieverOutput(DataClass):
doc_indices: List[int] = field(metadata={"desc": "List of document indices"})
doc_scores: Optional[List[float]] = field(
default=None, metadata={"desc": "List of document scores"}
)
query: Optional[RetrieverQueryType] = field(
default=None, metadata={"desc": "The query used to retrieve the documents"}
)
documents: Optional[List[RetrieverDocumentType]] = field(
default=None, metadata={"desc": "List of retrieved documents"}
)
RetrieverOutputType = List[RetrieverOutput] # so to support multiple queries at once
Document and TextSplitter
If your documents (in text format) are too large, it is common practise to first use TextSplitter to split the text into smaller chunks.
Please refer to the Text Splitter tutorial on how to use it.
Retriever Base Class¶
Functionally, the base retriever Retriever defines another required method build_index_from_documents where the subclass will prepare the retriever for the actual retrieval calls.
Optionally, the subclass can implement save_to_file and load_from_file to save and load the retriever to/from disk.
As the retriever is a subclass of component, you already inherited powerful serialization and deserialization methods such as to_dict, from_dict, and from_config to help
with the saving and loading process. As for helper attributes, we have indexed and index_keys to differentiate if the retriever is ready for retrieval and the attributes that are key to restore the functionality/states of the retriever.
It is up the subclass to decide how to decide the storage of the index, it can be in-memory, local disk, or cloud storage, or save as json or pickle file or even a db table.
As an example, BM25Retriever has the following key attributes to index.
class Retriever(Component, Generic[RetrieverDocumentType, RetrieverQueryType]):
...
def call(
self,
input: RetrieverQueriesType,
top_k: Optional[int] = None,
**kwargs,
) -> RetrieverOutputType:
raise NotImplementedError(f"retrieve is not implemented")
async def acall(
self,
input: RetrieverQueriesType,
top_k: Optional[int] = None,
**kwargs,
) -> RetrieverOutputType:
raise NotImplementedError(f"Async retrieve is not implemented")
self.index_keys = ["nd", "t2d", "idf","doc_len","avgdl","total_documents","top_k","k1","b","epsilon","indexed"]
Experiment data¶
In this note, we will use the following documents and queries for demonstration:
query_1 = "What are the benefits of renewable energy?" # gt is [0, 3]
query_2 = "How do solar panels impact the environment?" # gt is [1, 2]
documents =[
{
"title": "The Impact of Renewable Energy on the Economy",
"content": "Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure."
},
{
"title": "Understanding Solar Panels",
"content": "Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels."
},
{
"title": "Pros and Cons of Solar Energy",
"content": "While solar energy offers substantial environmental benefits, such as reducing carbon footprints and pollution, it also has downsides. The production of solar panels can lead to hazardous waste, and large solar farms require significant land, which can disrupt local ecosystems."
},
{
"title": "Renewable Energy and Its Effects",
"content": "Renewable energy sources like wind, solar, and hydro power play a crucial role in combating climate change. They do not produce greenhouse gases during operation, making them essential for sustainable development. However, the initial setup and material sourcing for these technologies can still have environmental impacts."
}
]
The first query should retrieve the first and the last document, and the second query should retrieve the second and the third document.
Documents filtering¶
Before using more advanced retrieval methods, it is common to filter the documents first. Document filtering is dependent on your data storage, whether it is in memory, local disk, or cloud database. For the cloud database, it is highly dependent on the database’s search and filter methods. And SQL-based search is common, scalable, and efficient.
Before you pass the documents or processed document chunks and embeddings to the retriever, you can filter the documents first by yourself.
from adalflow.core.db import LocalDB
from adalflow.core.types import Document
db = LocalDB(items=[Document(text=doc["content"], meta_data={"title": doc["title"]}) for doc in documents])
print(db)
Retriever in Action¶
All of our retrievers are subclassed from the base retriever, and they are located in the components.retriever module.
You can skim through their implementations here: retriever.
Currently only BM25Retriever needs to have its own save_to_file and load_from_file to avoid recomputation again.
The FAISSRetriever will work with a database instead to store the embeddings and it alleviates the need for the retriever to deal with states saving.
FAISSRetriever¶
First, let’s do semantic search, here we will use in-memory FAISSRetriever.
FAISS retriever takes embeddings which can be List[float] or np.ndarray and build an index using FAISS library.
The query can take both embeddings and str formats.
Note
faiss package is optional in our library. When you want to use it, ensure you have it installed in your env.
We will quickly prepare the embeddings of the above documents using content field.
from adalflow.core.embedder import Embedder
from adalflow.core.types import ModelClientType
model_kwargs = {
"model": "text-embedding-3-small",
"dimensions": 256,
"encoding_format": "float",
}
embedder = Embedder(model_client =ModelClientType.OPENAI(), model_kwargs=model_kwargs)
output = embedder(input=[doc["content"] for doc in documents])
documents_embeddings = [x.embedding for x in output.data]
For the initialization, a retriever can take both its required documents along with hyperparmeters including top_k.
The documents field is optional. Let’s pass it all from __init__ first:
from adalflow.components.retriever import FAISSRetriever
retriever = FAISSRetriever(top_k=2, embedder=embedder, documents=documents_embeddings)
print(retriever)
The printout:
FAISSRetriever(
top_k=2, metric=prob, dimensions=256, total_documents=4
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
)
We can also pass the documents using build_index_from_documents method after the initialization.
This is helpful when your retriever would need to work with different pool of documents each time.
retriever_1 = FAISSRetriever(top_k=2, embedder=embedder)
retriever_1.build_index_from_documents(documents=documents_embeddings)
Now, we will do the retriever, the input can either be a single query or a list of queries:
output_1 = retriever(input=query_1)
output_2 = retriever(input=query_2)
output_3 = retriever(input = [query_1, query_2])
print(output_1)
print(output_2)
print(output_3)
The printout is:
[RetrieverOutput(doc_indices=[0, 3], doc_scores=[0.8119999766349792, 0.7749999761581421], query='What are the benefits of renewable energy?', documents=None)]
[RetrieverOutput(doc_indices=[2, 1], doc_scores=[0.8169999718666077, 0.8109999895095825], query='How do solar panels impact the environment?', documents=None)]
[RetrieverOutput(doc_indices=[0, 3], doc_scores=[0.8119999766349792, 0.7749999761581421], query='What are the benefits of renewable energy?', documents=None), RetrieverOutput(doc_indices=[2, 1], doc_scores=[0.8169999718666077, 0.8109999895095825], query='How do solar panels impact the environment?', documents=None)]
In default, the score is a simulated probabity in range [0, 1] using consine similarity. The higher the score, the more relevant the document is to the query.
You can check the retriever for more type of scores.
BM25Retriever¶
So the semantic search works pretty well. We will see how BM25Retriever works in comparison.
We reimplemented the code in [9] with one improvement: instead of using text.split(" "), we use tokenizer to split the text. Here is a comparison of how they different:
from adalflow.components.retriever.bm25_retriever import split_text_by_word_fn_then_lower_tokenized, split_text_by_word_fn
query_1_words = split_text_by_word_fn(query_1)
query_1_tokens = split_text_by_word_fn_then_lower_tokenized(query_1)
Output:
['what', 'are', 'the', 'benefits', 'of', 'renewable', 'energy?']
['what', 'are', 'the', 'benef', 'its', 'of', 're', 'new', 'able', 'energy', '?']
We prepare the retriever:
from adalflow.components.retriever import BM25Retriever
document_map_func = lambda x: x["content"]
bm25_retriever = BM25Retriever(top_k=2, documents=documents, document_map_func=document_map_func)
print(bm25_retriever)
It takes document_map_func to map the documents to the text format the retriever can work with.
The output is:
BM25Retriever(top_k=2, k1=1.5, b=0.75, epsilon=0.25, use_tokenizer=True, total_documents=4)
Now we call the retriever exactly the same way as we did with the FAISS retriever:
output_1 = bm25_retriever(input=query_1)
output_2 = bm25_retriever(input=query_2)
output_3 = bm25_retriever(input = [query_1, query_2])
print(output_1)
print(output_2)
print(output_3)
The printout is:
[RetrieverOutput(doc_indices=[2, 1], doc_scores=[2.151683837681807, 1.6294762236217233], query='What are the benefits of renewable energy?', documents=None)]
[RetrieverOutput(doc_indices=[3, 2], doc_scores=[1.5166601493236314, 0.7790170272403408], query='How do solar panels impact the environment?', documents=None)]
[RetrieverOutput(doc_indices=[2, 1], doc_scores=[2.151683837681807, 1.6294762236217233], query='What are the benefits of renewable energy?', documents=None), RetrieverOutput(doc_indices=[3, 2], doc_scores=[1.5166601493236314, 0.7790170272403408], query='How do solar panels impact the environment?', documents=None)]
Here we see the first query returns [2, 1] while the ground truth is [0, 3]. The second query returns [3, 2] while the ground truth is [1, 2].
The performance is quite disappointing. BM25 is known for lack of semantic understanding and does not consider context.
We tested on the shorter and almost key-word like version of our queries and use both the title and content, and it gives the right response using the tokenized split.
query_1_short = "renewable energy?" # gt is [0, 3]
query_2_short = "solar panels?" # gt is [1, 2]
document_map_func = lambda x: x["title"] + " " + x["content"]
bm25_retriever.build_index_from_documents(documents=documents, document_map_func=document_map_func)
This time the retrieval gives us the right answer.
[RetrieverOutput(doc_indices=[0, 3], doc_scores=[0.9498793313012154, 0.8031794089550072], query='renewable energy?', documents=None)]
[RetrieverOutput(doc_indices=[2, 1], doc_scores=[0.5343238380789569, 0.4568096570283078], query='solar panels?', documents=None)]
Reranker as Retriever¶
Semantic search works well, and reranker basd on mostly cross-encoder model is supposed to work even better.
We have integrated two rerankers: BAAI/bge-reranker-base [10] hosted on transformers and rerankers provided by Cohere [11].
These models follow the ModelClient protocol and are directly accessible as retriever from RerankerRetriever.
Reranker ModelClient Integration
A reranker will take ModelType.RERANKER and the standard AdalFlow library requires it to have four arguments in the model_kwargs:
['model', 'top_k', 'documents', 'query']. It is in the ModelClient which converts AdalFlow’s standard arguments to the model’s specific arguments.
If you want to intergrate your reranker, either locally or using APIs, check out TransformersClient and
CohereAPIClient for how to do it.
To use it from the RerankerRetriever, we only need to pass the model along with other arguments who does not
require conversion in the model_kwargs. Here is how we use model rerank-english-v3.0 from Cohere(Make sure you have the cohere sdk installed and prepared your api key):
from adalflow.components.retriever import RerankerRetriever
model_client = ModelClientType.COHERE()
model_kwargs = {"model": "rerank-english-v3.0"}
reranker = RerankerRetriever(
top_k=2, model_client=model_client, model_kwargs=model_kwargs
)
print(reranker)
The printout:
RerankerRetriever(
top_k=2, model_kwargs={'model': 'rerank-english-v3.0'}, model_client=CohereAPIClient(), total_documents=0
(model_client): CohereAPIClient()
)
Now we build the index and do the retrieval:
document_map_func = lambda x: x["content"]
reranker.build_index_from_documents(documents=documents, document_map_func=document_map_func)
output_1 = reranker(input=query_1)
output_2 = reranker(input=query_2)
output_3 = reranker(input = [query_1, query_2])
From the structure after adding documents we see the reranker has passed the documents to the model_kwargs so that it can send it all to the ModelClient.
RerankerRetriever(
top_k=2, model_kwargs={'model': 'rerank-english-v3.0', 'documents': ['Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.', 'Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.', 'While solar energy offers substantial environmental benefits, such as reducing carbon footprints and pollution, it also has downsides. The production of solar panels can lead to hazardous waste, and large solar farms require significant land, which can disrupt local ecosystems.', 'Renewable energy sources like wind, solar, and hydro power play a crucial role in combating climate change. They do not produce greenhouse gases during operation, making them essential for sustainable development. However, the initial setup and material sourcing for these technologies can still have environmental impacts.']}, model_client=CohereAPIClient(), total_documents=4
(model_client): CohereAPIClient()
)
From the results we see it gets the right answer and has a close to 1 score.
[RetrieverOutput(doc_indices=[0, 3], doc_scores=[0.99520767, 0.9696708], query='What are the benefits of renewable energy?', documents=None)]
[RetrieverOutput(doc_indices=[1, 2], doc_scores=[0.98742366, 0.9701269], query='How do solar panels impact the environment?', documents=None)]
[RetrieverOutput(doc_indices=[0, 3], doc_scores=[0.99520767, 0.9696708], query='What are the benefits of renewable energy?', documents=None), RetrieverOutput(doc_indices=[1, 2], doc_scores=[0.98742366, 0.9701269], query='How do solar panels impact the environment?', documents=None)]
Now let us see how the ``BAAI/bge-reranker-base` from local transformers model works:
model_client = ModelClientType.TRANSFORMERS()
model_kwargs = {"model": "BAAI/bge-reranker-base"}
reranker = RerankerRetriever(
top_k=2,
model_client=model_client,
model_kwargs=model_kwargs,
documents=documents,
document_map_func=document_map_func,
)
print(reranker)
The printout:
RerankerRetriever(
top_k=2, model_kwargs={'model': 'BAAI/bge-reranker-base', 'documents': ['Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.', 'Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.', 'While solar energy offers substantial environmental benefits, such as reducing carbon footprints and pollution, it also has downsides. The production of solar panels can lead to hazardous waste, and large solar farms require significant land, which can disrupt local ecosystems.', 'Renewable energy sources like wind, solar, and hydro power play a crucial role in combating climate change. They do not produce greenhouse gases during operation, making them essential for sustainable development. However, the initial setup and material sourcing for these technologies can still have environmental impacts.']}, model_client=TransformersClient(), total_documents=4
(model_client): TransformersClient()
)
Here is the retrieval result:
[RetrieverOutput(doc_indices=[0, 3], doc_scores=[0.9996004700660706, 0.9950029253959656], query='What are the benefits of renewable energy?', documents=None)]
[RetrieverOutput(doc_indices=[2, 0], doc_scores=[0.9994490742683411, 0.9994476437568665], query='How do solar panels impact the environment?', documents=None)]
It missed one at the second query, but it is at the top 3. Semantically, these documents might be close. If we use top_k = 3, the genearator might be able to filter out the irrelevant one and eventually give out the right final response. Also, if we use both the title and content, it will also got the right response.
LLM as Retriever¶
There are differen ways to use LLM as a retriever:
Directly show it of all documents and query and ask it to return the indices of the top_k as a list.
Put the query and document a pair and ask it to do a yes and no. Additionally, we can use its logprobs of the yes token to get a probability-like score. We will implement this in the near future, for now, you can refer [8] to implement it yourself.
For the first case, with out prompt and zero-shot, gpt-3.5-turbo is not working as well as gpt-4o which got both answers right. Here is our code:
from adalflow.components.retriever import LLMRetriever
model_client = ModelClientType.OPENAI()
model_kwargs = {
"model": "gpt-4o",
}
document_map_func = lambda x: x["content"]
llm_retriever = LLMRetriever(
top_k=2,
model_client=model_client,
model_kwargs=model_kwargs,
documents=documents,
document_map_func=document_map_func
)
print(llm_retriever)
The printout:
LLMRetriever(
top_k=2, total_documents=4,
(generator): Generator(
model_kwargs={'model': 'gpt-4o'},
(prompt): Prompt(
template: <SYS>
You are a retriever. Given a list of documents, you will retrieve the top_k {{top_k}} most relevant documents and output the indices (int) as a list:
[<index of the most relevant with top_k options>]
<Documents>
{% for doc in documents %}
```Index {{ loop.index - 1 }}. {{ doc }}```
{% endfor %}
</Documents>
</SYS>
Query: {{ input_str }}
You:
, preset_prompt_kwargs: {'top_k': 2, 'documents': ['Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.', 'Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.', 'While solar energy offers substantial environmental benefits, such as reducing carbon footprints and pollution, it also has downsides. The production of solar panels can lead to hazardous waste, and large solar farms require significant land, which can disrupt local ecosystems.', 'Renewable energy sources like wind, solar, and hydro power play a crucial role in combating climate change. They do not produce greenhouse gases during operation, making them essential for sustainable development. However, the initial setup and material sourcing for these technologies can still have environmental impacts.']}, prompt_variables: ['documents', 'top_k', 'input_str']
)
(model_client): OpenAIClient()
(output_processors): ListParser()
)
)
Here is the response:
[RetrieverOutput(doc_indices=[0, 3], doc_scores=None, query='What are the benefits of renewable energy?', documents=None)]
[RetrieverOutput(doc_indices=[1, 2], doc_scores=None, query='How do solar panels impact the environment?', documents=None)]
We can call the retriever with different model without reinitializing the retriever. Here is how we do it with gpt-3.5-turbo:
model_kwargs = {
"model": "gpt-3.5-turbo",
}
output_1 = llm_retriever(model_kwargs=model_kwargs, input=query_1)
output_2 = llm_retriever(model_kwargs=model_kwargs, input=query_2)
The response is:
[RetrieverOutput(doc_indices=[0, 1], doc_scores=None, query='What are the benefits of renewable energy?', documents=None)]
[RetrieverOutput(doc_indices=[1, 2], doc_scores=None, query='How do solar panels impact the environment?', documents=None)]
Qdrant Retriever¶
You can retrieve documents loaded into your Qdrant collections using the QdrantRetriever.
Note
Install the qdrant-client package in your project to use this retriever.
The retriever supports any embeddings provider. The field to be returned from the Qdrant payload can be configured along with other parameters like filters.
from adalflow.components.retriever import QdrantRetriever
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
qdrant_retriever = QdrantRetriever(
collection_name="{collection_name}",
client=client,
embedder=embedder,
top_k=5,
text_key="content",
)
print(qdrant_retriever)
The output is:
QdrantRetriever(
(_embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
)
We can invoke the Qdrant retriever like the others:
output_1 = qdrant_retriever(input=query_1)
output_2 = qdrant_retriever(input=query_2)
output_3 = qdrant_retriever(input = [query_1, query_2])
You can use filters to further refine the search results as per requirements when setting up the retriever.
from qdrant_client import models
qdrant_retriever = QdrantRetriever(
collection_name="{collection_name}",
client=client,
embedder=embedder,
text_key="content",
filter=models.Filter(
must=[
models.FieldCondition(
key="category",
match=models.MatchValue(value="facts"),
),
models.FieldCondition(
key="weight",
range=models.Range(gte=0.98),
),
]
)
)
LanceDBRetriever¶
To perform semantic search using LanceDB, we will use LanceDBRetriever.
The LanceDBRetriever is designed for efficient vector-based retrieval with LanceDB, leveraging embeddings that can be either List[float] or np.ndarray.
LanceDB supports in-memory and disk-based configurations and can handle large-scale data with high retrieval speed.
Note
The lancedb package is optional. Ensure you have it installed in your environment to use LanceDBRetriever.
We will prepare the document embeddings using the content field.
from adalflow.core.embedder import Embedder
from adalflow.core.types import ModelClientType
model_kwargs = {
"model": "text-embedding-3-small",
"dimensions": 256,
"encoding_format": "float",
}
embedder = Embedder(model_client=ModelClientType.OPENAI(), model_kwargs=model_kwargs)
output = embedder(input=[doc["content"] for doc in documents])
After initializing the LanceDB retriever, we can add documents and perform retrievals. The retriever can be set with its top-k hyperparameter during initialization.
from adalflow.components.retriever import LanceDBRetriever
retriever = LanceDBRetriever(embedder=embedder, dimensions=256, db_uri="/tmp/lancedb", top_k=2)
print(retriever)
The printout:
LanceDBRetriever(
top_k=2, dimensions=256, total_documents=0
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
)
We can add documents to LanceDB and use the retriever for query-based searches.
retriever.add_documents(documents)
# Perform retrieval queries
output_1 = retriever.retrieve(query="What are the benefits of renewable energy?")
output_2 = retriever.retrieve(query="How do solar panels impact the environment?")
print("Query 1 Results:", output_1)
print("Query 2 Results:", output_2)
This setup allows the LanceDBRetriever to function as an efficient tool for large-scale, embedding-based document retrieval within LanceDB.
PostgresRetriever¶
Coming soon.
Use Score Threshold instead of top_k¶
In some cases, when the retriever has a computed score and you might prefer to use the score instead of top_k to filter out the relevant documents.
To do so, you can simplify set the top_k to the full size of the documents and use a post-processing step or a component(to chain with the retriever) to filter out the documents with the score below the threshold.
Use together with Database¶
When the scale of data is large, we will use a database to store the computed embeddings and indexes from the documents.
With LocalDB¶
We have previously computed embeddings, now let us LocalDB to help with the persistence.
(Although you can totally persist them yourself such as using pickle).
Additionally, LocalDB help us keep track of our initial documents and its transformed documents.
References
API References