
LLM Evaluation¶
“You cannot optimize what you cannot measure”.
This is especially true in the context of LLMs, which have become increasingly popular due to their impressive performance on a wide range of tasks. Evaluating LLMs and their applications is crucial in both research and production to understand their capabilities and limitations. Overall, such evaluation is a complex and multifaceted process. Below, we provide a guideline for evaluating LLMs and their applications, incorporating aspects outlined by Chang et al. [1] and more for RAG evaluation.
What to evaluate: the tasks and capabilities that LLMs are evaluated on.
Where to evaluate: the datasets and benchmarks that are used for evaluation.
How to evaluate: the protocols and metrics that are used for evaluation.
Tasks and Capabilities¶
Below are some commonly evaluated tasks and capabilities of LLMs summarized in [1].
Natural language understanding (NLU) tasks, such as text classification and sentiment analysis, which evaluate the LLM’s ability to understand natural language.
Natural language generation (NLG) tasks, such as text summarization, translation, and question answering, which evaluate the LLM’s ability to generate natural language.
Reasoning tasks, such as mathematical, logic, and common-sense reasoning, which evaluate the LLM’s ability to perform reasoning and inference to obtain the correct answer.
Robustness, which evaluate the LLM’s ability to generalize to unexpected inputs.
Fairness, which evaluate the LLM’s ability to make unbiased decisions.
Domain adaptation, which evaluate the LLM’s ability to adapt from general language to specific new domains, such as medical or legal texts, coding, etc.
Agent applications, which evaluate the LLM’s ability to use external tools and APIs to perform tasks, such as web search.
For a more detailed and comprehensive description of the tasks and capabilities that LLMs are evaluated on, please refer to the review papers by Chang et al. [1] and Guo et al. [2]. RRAG [21] evaluation differs as it introduces a retrieval component to the pipeline, which we will discuss in the next section.
Datasets and Benchmarks¶
The selection of datasets and benchmarks [19] is important, as it determines the quality and relevance of the evaluation.
To comprehensively assess the capabilities of LLMs, researchers typically utilize benchmarks and datasets that span a broad spectrum of tasks. For example, in the GPT-4 technical report [3], the authors employed a variety of general language benchmarks, such as MMLU [4], and academic exams, such as the SAT, GRE, and AP courses, to evaluate the diverse capabilities of GPT-4. Below are some commonly used datasets and benchmarks for evaluating LLMs.
MMLU [4], which evaluates the LLM’s ability to perform a wide range of language understanding tasks.
HumanEval [5], which measures the LLM’s capability in writing Python code.
HELM, which evaluates LLMs across diverse aspects such as language understanding, generation, common-sense reasoning, and domain adaptation.
Chatbot Arena, which is an open platform to evaluate LLMs through human voting.
API-Bank, which evaluates LLMs’ ability to use external tools and APIs to perform tasks.
Please refer to the review papers (Chang et al. [1], Guo et al. [2], and Liu et al. [6]) for a more comprehensive overview of the datasets and benchmarks used in LLM evaluations. Additionally, a lot of datasets are readily accessible via the Hugging Face Datasets library. For instance, the MMLU dataset can be easily loaded from the Hub using the following code snippet.
1from datasets import load_dataset
2dataset = load_dataset(path="cais/mmlu", name='abstract_algebra')
3print(dataset["test"])
The output will be a Dataset object containing the test set of the MMLU dataset.
Datasets for RAG Evaluation
According to RAGEval [21], the evaluation dataset can be categorized into two types: traditional open-domain QA datasets and scenario-specific RAG evaluation datasets.
Traditional open-domain QA datasets include:
HotPotQA: A dataset for multi-hop question answering.
Natural Questions: A dataset for open-domain question answering.
MS MARCO: A dataset for passage retrieval and question answering.
2WikiMultiHopQA: A dataset for multi-hop question answering.
KILT: A benchmark for knowledge-intensive language tasks.
Scenario-specific RAG evaluation datasets,
RGB: assesses LLMs’ ability to lever-age retrieved information, focusing on noise ro-bustness and information integration.
CRAG: increases domain coverage and introducesmock APIs to simulate real-world retrieval sce-narios.
Evaluation Metrics¶
Evaluation methods can be divided into automated evaluation and human evaluation (Chang et al. [1] and Liu et al. [6]).
Automated evaluation typically involves using metrics such as accuracy and BERTScore or employing an LLM as the judge, to quantitatively assess the performance of LLMs on specific tasks. Human evaluation, on the other hand, involves human in the loop to evaluate the quality of the generated text or the performance of the LLM.
Here, we categorize the automated evaluation methods as follows:
For classicial NLU tasks, such as text classification and sentiment analysis, you can use metrics such as accuracy, F1-score, and ROC-AUC to evaluate the performance of LLM response just like you would do using non-genAI models. You can check out TorchMetrics.
For NLG tasks, such as text summarization, translation, and question answering: (1) you can use metrics such as ROUGE, BLEU, METEOR, and BERTScore, perplexity,
LLMasJudgeetc to evaluate the quality of the generated text with respect to the reference text. Or usingGEvalLLMJudgeto evaluate the generated text even without reference text.For RAG (Retrieval-Augmented Generation) pipelines, you can use metrics such as
RetrieverRecall,AnswerMatchAcc, andLLMasJudgeto evaluate the quality of the retrieved context and the generated answer.
You can also check out the metrics provided by Hugging Face Metrics, RAGAS, TorchMetrics, ARES, SemScore, RGB, etc.
NLG Evaluation¶
Classicial String Metrics¶
The simplest metric would be EM AnswerMatchAcc: This calculates the exact match accuracy or fuzzy match accuracy of the generated answers by comparing them to the ground truth answers.
More advanced traditional metrics, such as F1, BLEU [8], ROUGE [9], [20], and METEOR [12], may fail to capture the semantic similarity between the reference text and the generated text, resulting in low correlation with human judgment.
You can use TorchMetrics [10] or Hugging Face Metrics to compute these metrics. For instance,
gt = "Brazil has won 5 FIFA World Cup titles"
pred = "Brazil is the five-time champion of the FIFA WorldCup."
def compute_rouge(gt, pred):
from torchmetrics.text.rouge import ROUGEScore
rouge = ROUGEScore()
return rouge(pred, gt)
def compute_bleu(gt, pred):
from torchmetrics.text.bleu import BLEUScore
bleu = BLEUScore()
return bleu([pred], [[gt]])
The output Rouge score is:
{'rouge1_fmeasure': tensor(0.2222), 'rouge1_precision': tensor(0.2000), 'rouge1_recall': tensor(0.2500), 'rouge2_fmeasure': tensor(0.), 'rouge2_precision': tensor(0.), 'rouge2_recall': tensor(0.), 'rougeL_fmeasure': tensor(0.2222), 'rougeL_precision': tensor(0.2000), 'rougeL_recall': tensor(0.2500), 'rougeLsum_fmeasure': tensor(0.2222), 'rougeLsum_precision': tensor(0.2000), 'rougeLsum_recall': tensor(0.2500)}
The output BLEU score is: 0.0
These two sentences totally mean the same, but it scored low in BLEU and ROUGE.
Embedding-based Metrics¶
To make up for this, embedding-based metrics or neural evaluators such as BERTScore was created. You can find BERTScore in both Hugging Face Metrics and TorchMetrics. BERTScore uses pre-trained contextual embeddings from BERT and matched words in generated text and reference text using cosine similarity.
def compute_bertscore(gt, pred):
r"""
https://lightning.ai/docs/torchmetrics/stable/text/bert_score.html
"""
from torchmetrics.text.bert import BERTScore
bertscore = BERTScore()
return bertscore([pred], [gt])
The output BERT score is:
{'precision': tensor(0.9752), 'recall': tensor(0.9827), 'f1': tensor(0.9789)}
This score does reflect the semantic similarity between the two sentences almost perfectly. However, the downside of all the above metrics is that you need to have a reference text to compare with. Labeling, such as creating a reference text, can be quite challenging in many NLG tasks, such as summarization.
LLM as Judge¶
Just as how LLM has made the AI tasks easier, it has made the evaluation of AI tasks easier too.
The real power of using LLM as judge is:
its adaptatibility compared with all the above metrics, it can be adapted to any task out of the box.
its flexibility and robustness at measuring. For many NLG tasks, there can only have multiple references or even countless correct reponses. Using traditional metrics can be very limiting.
Less training data. Align an LLM judge to your task using (question, ground truth, generated text, gt_score) tuples takes less data than finetune a model like BERTScore.
Evaluating an LLM application using an LLM as a judge is similar to building an LLM task pipeline. Developers need to understand the underlying prompt used by the LLM judge to determine whether the default judge is sufficient or if customization is required.
After reviewing research papers and existing libraries, we found no solution that provides these evaluators with complete clarity without requiring developers to install numerous additional dependencies. With this in mind, AdalFlow decided to offer a comprehensive set of LLM evaluators rather than directing our developers to external evaluation packages.
You can use an LLM as a judge in cases where you have a reference text or not. The key is to clearly define the metric using text.
We are developing LLM judge to replace human labelers, boosting efficiency and reducing financial costs.
The most straightforward LLM judge predicts a yes/no answer or a float score in range [0, 1] based on the comparison between the generated text and the reference text for a given judgment query.
Here is AdalFlow’s default judegement query:
DEFAULT_JUDGEMENT_QUERY = "Does the predicted answer contain the ground truth answer? Say True if yes, False if no."
AdalFlow provides a very customizable LLM judge, which can be used in three ways:
With question, ground truth, and generated text
Without question, with ground truth, and generated text, mainly matching the ground truth and the generated text
With question, without ground truth, with generated text, mainly matching between the questiona and the generated text
And you can customize the judgement_query towards your use case or even the whole llm template.
AdalFlow LLM judge returns LLMJudgeEvalResult which has three fields: 1. avg_score: average score of the generated text 2. judgement_score_list: list of scores for each generated text 3. confidence_interval: a tuple of the 95% confidence interval of the scores
DefaultLLMJudge is an LLM task pipeline that takes a single question(optional), ground truth(optional), and generated text and returns the float score in range [0,1].
You can use it as an eval_fn for AdalFlow Trainer.
LLMAsJudge is an evaluator that takes a list of inputs and returns a list of LLMJudgeEvalResult. Besides of the score, it computes the confidence interval of the scores.
Case 1: With References
Now, you can use the following code to calculate the final score based on the judgment query:
def compute_llm_as_judge():
import adalflow as adal
from adalflow.eval.llm_as_judge import LLMasJudge, DefaultLLMJudge
from adalflow.components.model_client import OpenAIClient
adal.setup_env()
questions = [
"Is Beijing in China?",
"Is Apple founded before Google?",
"Is earth flat?",
]
pred_answers = ["Yes", "Yes, Appled is founded before Google", "Yes"]
gt_answers = ["Yes", "Yes", "No"]
llm_judge = DefaultLLMJudge(
model_client=OpenAIClient(),
model_kwargs={
"model": "gpt-4o",
"temperature": 1.0,
"max_tokens": 10,
},
)
llm_evaluator = LLMasJudge(llm_judge=llm_judge)
print(llm_judge)
eval_rslt = llm_evaluator.compute(
questions=questions, gt_answers=gt_answers, pred_answers=pred_answers
)
print(eval_rslt)
To ensure more rigor, you can compute a 95% confidence interval for the judgment score. When the evaluation dataset is small, the confidence interval may have a large range, indicating that the judgment score is not very reliable.
The output will be:
LLMJudgeEvalResult(avg_score=0.6666666666666666, judgement_score_list=[1, 1, 0], confidence_interval=(0.013333333333333197, 1))
This type of LLM judeg is seen in text-grad [17]. You can view the prompt we used simply using print(llm_judge):
DefaultLLMJudge(
judgement_query= Does the predicted answer contain the ground truth answer? Say True if yes, False if no.,
(model_client): OpenAIClient()
(llm_evaluator): Generator(
model_kwargs={'model': 'gpt-4o', 'temperature': 1.0, 'max_tokens': 10}, trainable_prompt_kwargs=['task_desc_str', 'examples_str']
(prompt): Prompt(
template: <START_OF_SYSTEM_PROMPT>
{# task desc #}
{{task_desc_str}}
{# examples #}
{% if examples_str %}
{{examples_str}}
{% endif %}
<END_OF_SYSTEM_PROMPT>
---------------------
<START_OF_USER>
{# question #}
{% if question_str is defined %}
Question: {{question_str}}
{% endif %}
{# ground truth answer #}
{% if gt_answer_str is defined %}
Ground truth answer: {{gt_answer_str}}
{% endif %}
{# predicted answer #}
Predicted answer: {{pred_answer_str}}
<END_OF_USER>
, prompt_kwargs: {'task_desc_str': 'You are an evaluator. Given the question(optional), ground truth answer(optional), and predicted answer, Does the predicted answer contain the ground truth answer? Say True if yes, False if no.', 'examples_str': None}, prompt_variables: ['task_desc_str', 'examples_str', 'pred_answer_str', 'question_str', 'gt_answer_str']
)
(model_client): OpenAIClient()
)
)
Case 2: Without Question
def compute_llm_as_judge_wo_questions():
from adalflow.eval.llm_as_judge import LLMasJudge, DefaultLLMJudge
from adalflow.components.model_client import OpenAIClient
llm_judge = DefaultLLMJudge(
model_client=OpenAIClient(),
model_kwargs={
"model": "gpt-4o",
"temperature": 1.0,
"max_tokens": 10,
},
jugement_query="Does the predicted answer means the same as the ground truth answer? Say True if yes, False if no.",
)
llm_evaluator = LLMasJudge(llm_judge=llm_judge)
print(llm_judge)
eval_rslt = llm_evaluator.compute(gt_answers=[gt], pred_answers=[pred])
print(eval_rslt)
The output will be:
LLMJudgeEvalResult(avg_score=1.0, judgement_score_list=[1], confidence_interval=(0, 1))
G_Eval¶
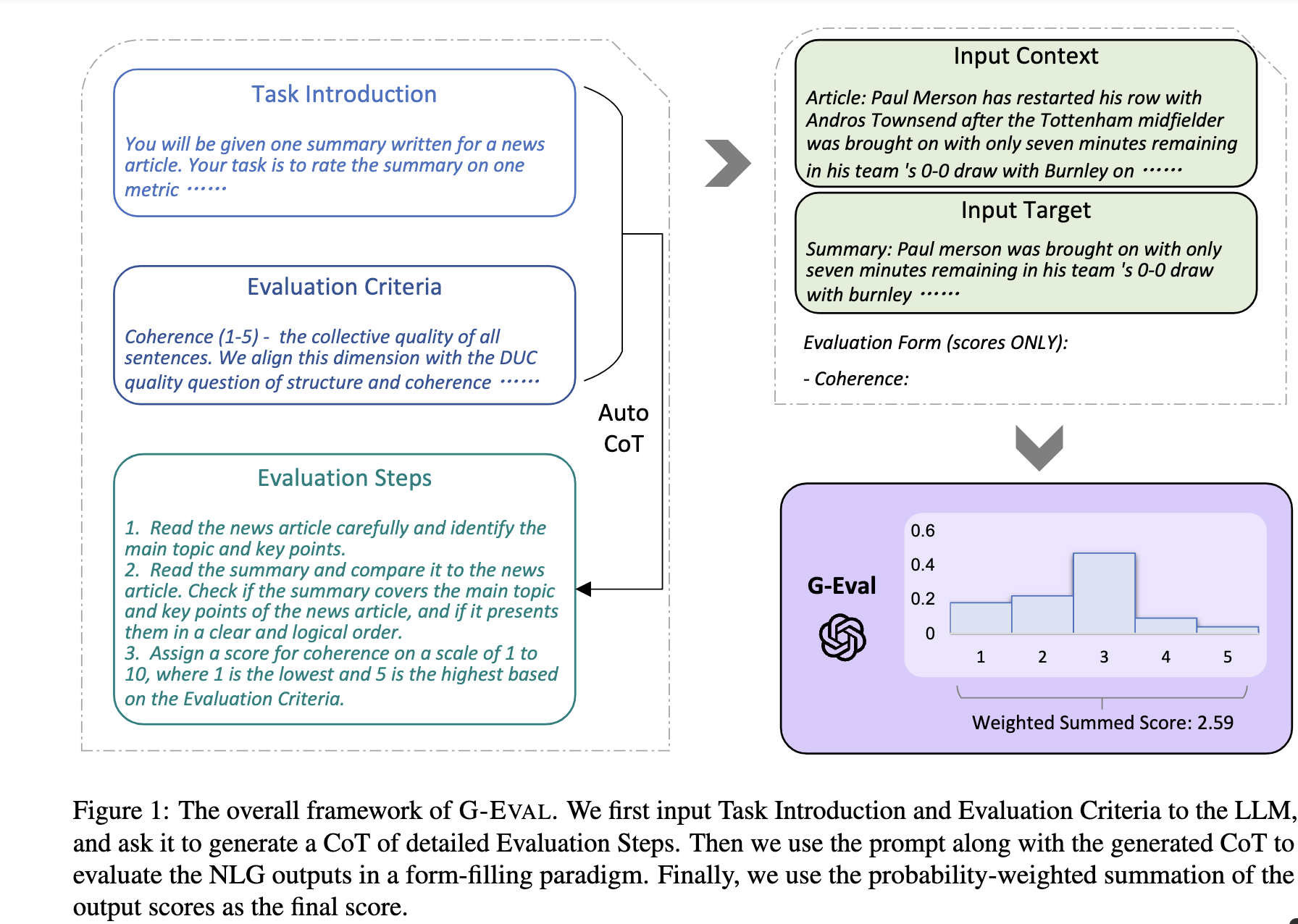
G-eval framework structure¶
If you have no reference text, you can also use G-eval [11] to evaluate the generated text on the fly. G-eval provided a way to evaluate:
relevance: evaluates how relevant the summarized text to the source text.
fluency: the quality of the summary in terms of grammar, spelling, punctuation, word choice, and sentence structure.
consistency: evaluates the collective quality of all sentences.
coherence: evaluates the the factual alignment between the summary and the summarized source.
In our library, we provides the prompt for task Summarization and Chatbot as default. We also map the score to the range [0, 1] for the ease of optimization.
Here is the code snippet to compute the G-eval score:
def compute_g_eval_summarization():
from adalflow.eval.g_eval import GEvalLLMJudge, GEvalJudgeEvaluator, NLGTask
model_kwargs = {
"model": "gpt-4o",
"n": 20,
"top_p": 1,
"max_tokens": 5,
"temperature": 1,
}
g_eval = GEvalLLMJudge(
default_task=NLGTask.SUMMARIZATION, model_kwargs=model_kwargs
)
print(g_eval)
input_template = """Source Document: {source}
Summary: {summary}
"""
input_str = input_template.format(
source="Paul Merson has restarted his row with Andros Townsend after the Tottenham midfielder was brought on with only seven minutes remaining in his team 's 0-0 draw with Burnley on Sunday . 'Just been watching the game , did you miss the coach ? # RubberDub # 7minutes , ' Merson put on Twitter . Merson initially angered Townsend for writing in his Sky Sports column that 'if Andros Townsend can get in ( the England team ) then it opens it up to anybody . ' Paul Merson had another dig at Andros Townsend after his appearance for Tottenham against Burnley Townsend was brought on in the 83rd minute for Tottenham as they drew 0-0 against Burnley Andros Townsend scores England 's equaliser in their 1-1 friendly draw with Italy in Turin on Tuesday night The former Arsenal man was proven wrong when Townsend hit a stunning equaliser for England against Italy and he duly admitted his mistake . 'It 's not as though I was watching hoping he would n't score for England , I 'm genuinely pleased for him and fair play to him \u00e2\u20ac\u201c it was a great goal , ' Merson said . 'It 's just a matter of opinion , and my opinion was that he got pulled off after half an hour at Manchester United in front of Roy Hodgson , so he should n't have been in the squad . 'When I 'm wrong , I hold my hands up . I do n't have a problem with doing that - I 'll always be the first to admit when I 'm wrong . ' Townsend hit back at Merson on Twitter after scoring for England against Italy Sky Sports pundit Merson ( centre ) criticised Townsend 's call-up to the England squad last week Townsend hit back at Merson after netting for England in Turin on Wednesday , saying 'Not bad for a player that should be 'nowhere near the squad ' ay @ PaulMerse ? ' Any bad feeling between the pair seemed to have passed but Merson was unable to resist having another dig at Townsend after Tottenham drew at Turf Moor .",
summary="Paul merson was brought on with only seven minutes remaining in his team 's 0-0 draw with burnley . Andros townsend scored the tottenham midfielder in the 89th minute . Paul merson had another dig at andros townsend after his appearance . The midfielder had been brought on to the england squad last week . Click here for all the latest arsenal news news .",
)
g_evaluator = GEvalJudgeEvaluator(llm_judge=g_eval)
response = g_evaluator(input_strs=[input_str])
print(f"response: {response}")
The output will be:
response: ({'Relevance': 0.4, 'Fluency': 0.3333333333333333, 'Consistency': 0.2, 'Coherence': 0.4, 'overall': 0.33333333333333337}, [{'Relevance': 0.4, 'Fluency': 0.3333333333333333, 'Consistency': 0.2, 'Coherence': 0.4, 'overall': 0.33333333333333337}])
print(g_eval) will be:
GEvalLLMJudge(
default_task= NLGTask.SUMMARIZATION, prompt_kwargs={'Relevance': {'task_desc_str': 'You will be given a summary of a text. Please evaluate the summary based on the following criteria:', 'evaluation_criteria_str': 'Relevance (1-5) - selection of important content from the source.\n The summary should include only important information from the source document.\n Annotators were instructed to penalize summaries which contained redundancies and excess information.', 'evaluation_steps_str': '1. Read the summary and the source document carefully.\n 2. Compare the summary to the source document and identify the main points of the article.\n 3. Assess how well the summary covers the main points of the article, and how much irrelevant or redundant information it contains.\n 4. Assign a relevance score from 1 to 5.', 'metric_name': 'Relevance'}, 'Fluency': {'task_desc_str': 'You will be given a summary of a text. Please evaluate the summary based on the following criteria:', 'evaluation_criteria_str': 'Fluency (1-3): the quality of the summary in terms of grammar, spelling, punctuation, word choice, and sentence structure.\n - 1: Poor. The summary has many errors that make it hard to understand or sound unnatural.\n - 2: Fair. The summary has some errors that affect the clarity or smoothness of the text, but the main points are still comprehensible.\n - 3: Good. The summary has few or no errors and is easy to read and follow.\n ', 'evaluation_steps_str': None, 'metric_name': 'Fluency'}, 'Consistency': {'task_desc_str': 'You will be given a summary of a text. Please evaluate the summary based on the following criteria:', 'evaluation_criteria_str': 'Consistency (1-5) - the factual alignment between the summary and the summarized source.\n A factually consistent summary contains only statements that are entailed by the source document.\n Annotators were also asked to penalize summaries that contained hallucinated facts. ', 'evaluation_steps_str': '1. Read the summary and the source document carefully.\n 2. Identify the main facts and details it presents.\n 3. Read the summary and compare it to the source document to identify any inconsistencies or factual errors that are not supported by the source.\n 4. Assign a score for consistency based on the Evaluation Criteria.', 'metric_name': 'Consistency'}, 'Coherence': {'task_desc_str': 'You will be given a summary of a text. Please evaluate the summary based on the following criteria:', 'evaluation_criteria_str': 'Coherence (1-5) - the collective quality of all sentences.\n We align this dimension with the DUC quality question of structure and coherence whereby "the summary should be well-structured and well-organized.\n The summary should not just be a heap of related information, but should build from sentence to a coherent body of information about a topic.', 'evaluation_steps_str': '1. Read the input text carefully and identify the main topic and key points.\n 2. Read the summary and assess how well it captures the main topic and key points. And if it presents them in a clear and logical order.\n 3. Assign a score for coherence on a scale of 1 to 5, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria.', 'metric_name': 'Coherence'}}
(model_client): OpenAIClient()
(llm_evaluator): Generator(
model_kwargs={'model': 'gpt-4o', 'n': 20, 'top_p': 1, 'max_tokens': 5, 'temperature': 1}, trainable_prompt_kwargs=[]
(prompt): Prompt(
template:
<START_OF_SYSTEM_PROMPT>
{# task desc #}
{{task_desc_str}}
---------------------
{# evaluation criteria #}
Evaluation Criteria:
{{evaluation_criteria_str}}
---------------------
{# evaluation steps #}
{% if evaluation_steps_str %}
Evaluation Steps:
{{evaluation_steps_str}}
---------------------
{% endif %}
{{input_str}}
{ # evaluation form #}
Evaluation Form (scores ONLY):
- {{metric_name}}:
Output the score only.
<END_OF_SYSTEM_PROMPT>
, prompt_variables: ['input_str', 'task_desc_str', 'evaluation_criteria_str', 'evaluation_steps_str', 'metric_name']
)
(model_client): OpenAIClient()
(output_processors): FloatParser()
)
)
Train/Align LLM Judge¶
We should better align the LLM judge with a human preference dataset that contains (generated text, ground truth text, score) triplets.
This process is the same as optimizing the task pipeline, where you can create an AdalComponent and call our Trainer to do the in-context learning.
From the printout, you can observe the two trainable_prompt_kwargs in the DefaultLLMJudge.
In this case, we may want to compute a correlation score between the human judge and the LLM judge. You have various options, such as:
Pearson Correlation Coefficient
Kendallrank correlation coefficient from ARES [14], particularly useful for ranking systems (Retrieval).
RAG Evaluation¶
RAG (Retrieval-Augmented Generation) pipelines are a combination of a retriever and a generator. The retriever retrieves relevant context from a large corpus, and the generator generates the final answer based on the retrieved context. When a retriever failed to retrieve relevant context, the generator may fail. Therefore, besides of evaluating RAG pipelines as a whole using NLG metrics, it is also important to evaluate the retriever and to optimize the evalulation metrics from both stages to best improve the final performance.
With GT for Retriever¶
For the retriever, the metrics used are nothing new but from the standard information retrieval/ranking literature. Often, we have
Recall@k: the proportion of relevant documents that are retrieved out of the total number of relevant documents.
Mean Reciprocal Rank(MRR@k), HitRate@k, etc.
NDCG@k
Precision@k, MAP@k etc.
For defails of these metrics, please refer to [18]. All of these metrics, you can also find at TorchMetrics.
For example, you can use the following code snippet to compute the recall@k the retriever component of the RAG pipeline for a single query if the ground truth context is provided. In this example, the retrieved contexts is a joined string of the retrieved context chunks, and the gt_contexts is a list of ground truth context chunks for each query.
from adalflow.eval import RetrieverRecall, RetrieverRelevance
retrieved_contexts = [
"Apple is founded before Google.",
"Feburary has 28 days in common years. Feburary has 29 days in leap years. Feburary is the second month of the year.",
]
gt_contexts = [
[
"Apple is founded in 1976.",
"Google is founded in 1998.",
"Apple is founded before Google.",
],
["Feburary has 28 days in common years", "Feburary has 29 days in leap years"],
]
retriever_recall = RetrieverRecall()
avg_recall, recall_list = retriever_recall.compute(retrieved_contexts, gt_contexts) # Compute the recall of the retriever
print(f"Recall: {avg_recall}, Recall List: {recall_list}")
The output will be:
For the first query, only one out of three relevant documents is retrieved, resulting in a recall of 0.33. For the second query, all relevant documents are retrieved, resulting in a recall of 1.0.
Without gt_contexts¶
RAGAS¶
Ideally, for each query, we will retrieve the top k (@k) chunks and to get the above score, we expect each query, retrieved chunk pair comes with a ground truth labeling. But this is highly unrealistic especially if corpora is large. If we have 100 test queries, and a corpus of size 1000 chunks, the pairs we need to annoate is 10^5. There are different strategies to handle this problem but we could not dive into all of them here.
There is one new way is to indirectly use the ground truth answers from the generator to evaluate the retriever. RAGAS framework provides one way to do this.
Recall = [GT statements that can be attributed to the retrieved context] / [GT statements]
There is also Context Relevance and Context Precision metrics in RAGAS.
LLM or model based judge for Retriever Recall¶
LLM judge with in-context prompting
LLM judge to directly straightforward way to evaluate the top k score on the fly.
We can create a subset of query, retrieved chunk pairs and manually label them, and we train an LLM judge to predict the score. If the judge can achieve a high accuracy then we are able to annotate any metric in the retriever given the query and the retrieved chunk pairs.
ARES with finetuned classifier with synthetic data
ARES [14] proposed to create a synthetic dataset from an in-domain corpora. The generated data represent both positive and negative examples of query–passage–answer triples` (e.g.,relevant/irrelevant passages and correct/incorrectanswers).
The synthetic dataset is used to train a classifier consists of embedding and a classification head. It claims to be able to adapt to other domains where the classifier is not trained on. The cost of this approach is quite low as you can compute the embedding for only once for each query and each chunk in the corpus.
RAGEval for vertical domain evaluation
RAGEVal [21] proposed a framework to synthesize vertical domain evaluation dataset such as finance, healthcare, legal etc where due to the privacy, it is challenging to create a large real-world dataset.
More
See the evaluation on datasets at Evaluating a RAG Pipeline.
Additionally, there are more research for RAG evaluation, such as SemScore [13], ARES [14], RGB [15], etc.
Note
GovTech Singapore provides a well-explained evaluation guideline [22] that aligns with our guideline but with more thereotical explanation on some metrics.
For Contributors¶
There are way too many metrics and evaluation methods that AdalFlow can cover in the library. We encourage contributors who work on evaluation research and production to build evaluator that is compatible with AdalFlow. This means that:
The evaluator can potentially output a single float score in range [0, 1] so that AdalFlow Trainer can use it to optimize the pipeline.
For using LLM as judge, the judge should be built similar to DefaultLLMJudge so that there are trainable_prompt_kwargs that users can further align the judge with human preference dataset.
For instance, for the research papers we have listed here, it would be great to have a version that is easily compatible with AdalFlow.
References¶
AdalFlow Eval API Reference
Other Evaluation Metrics libraries