
Embedder¶
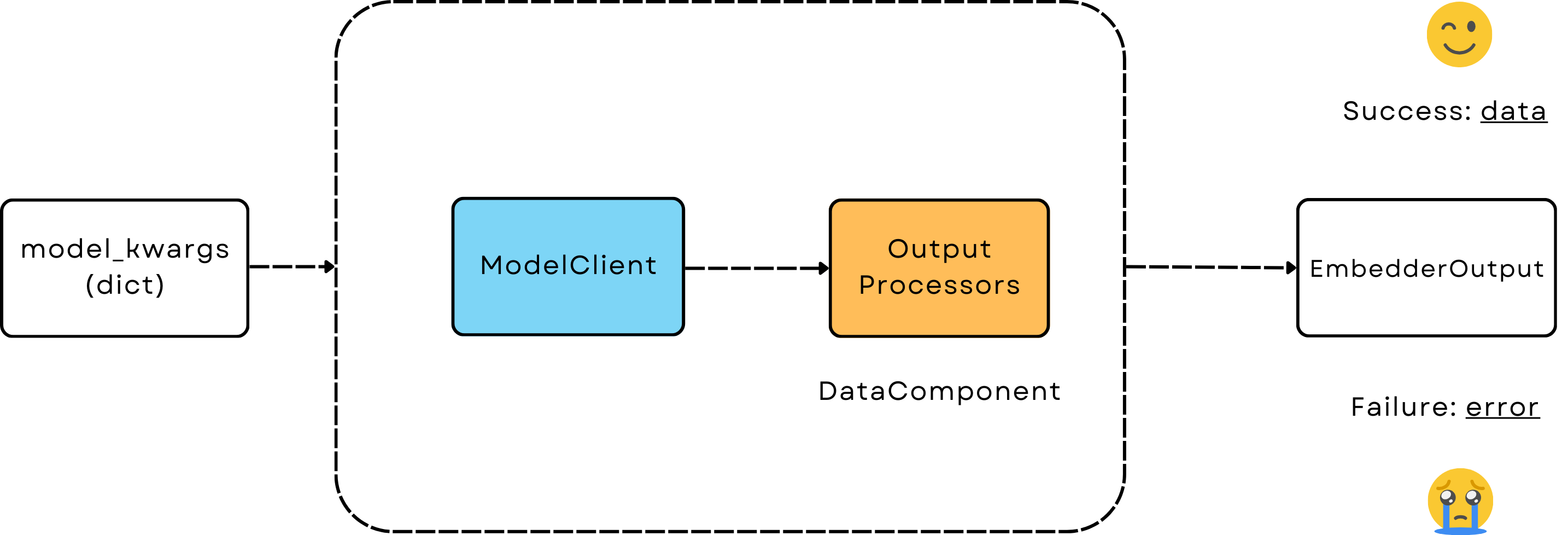
Embedder - Converts a list of strings into a list of vectors with embedding models.¶
Introduction¶
core.embedder.Embedder allows developers to use different embedding models easily.
Like Generator, Embedder is a user-facing component that orchestrates embedding models via ModelClient and output_processors, it outputs EmbedderOutput.
Unlike Generator which is trainable, Embedder is just a DataComponent that only transforms input strings into embeddings/vectors.
By switching the ModelClient, you can use different embedding models in your task pipeline easily, or even embedd different data such as text, image, etc.
For end developers, most likely you want to use ToEmbeddings together with Embedder as it (1) directly supports a sequence of Document objects, and (2) it handles batch processing out of box.
Document is a container that AdalFlow uses to also process data in TextSplitter which are often required in a RAG pipeline.
We currently support all embedding models from OpenAI and ‘thenlper/gte-base’ from HuggingFace transformers.
We will use these two to demonstrate how to use Embedder. For the local model, you need to ensure you have transformers installed.
Use Embedder¶
OpenAI Embedding Model¶
Before you start ensure you config the API key either in the environment variable or .env file, or directly pass it to the OpenAIClient.
from adalflow.core.embedder import Embedder
from adalflow.components.model_client import OpenAIClient
from adalflow.utils import setup_env # ensure you setup OPENAI_API_KEY in your project .env file
setup_env()
model_kwargs = {
"model": "text-embedding-3-small",
"dimensions": 256,
"encoding_format": "float",
}
query = "What is LLM?"
queries = [query] * 100
embedder = Embedder(model_client=OpenAIClient(), model_kwargs=model_kwargs)
You can use print(embedder) to visualize the structure. The output will be:
Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
Embed single query: Run the embedder and print the length and embedding dimension of the output.
output = embedder(query)
print(output.length, output.embedding_dim, output.is_normalized)
# 1 256 True
Embed a single batch of queries:
output = embedder(queries)
print(output.length, output.embedding_dim)
# 100 256
Local Model¶
Set up the embedder with the local model.
from adalflow.core.embedder import Embedder
from adalflow.components.model_client import TransformersClient
model_kwargs = {"model": "thenlper/gte-base"}
local_embedder = Embedder(model_client=TransformersClient(), model_kwargs=model_kwargs)
Now, call the embedder with the same query and queries.
output = local_embedder(query)
print(output.length, output.embedding_dim, output.is_normalized)
# 1 768 True
output = local_embedder(queries)
print(output.length, output.embedding_dim, output.is_normalized)
# 100 768 True
Use Output Processors¶
If we want to decreate the embedding dimension to only 256 to save memory, we can customize an additional output processing step and pass it to embedder via the output_processors argument.
from adalflow.core.types import Embedding, EmbedderOutput
from adalflow.core.functional import normalize_vector
from typing import List
from adalflow.core.component import DataComponent
from copy import deepcopy
class DecreaseEmbeddingDim(DataComponent):
def __init__(self, old_dim: int, new_dim: int, normalize: bool = True):
super().__init__()
self.old_dim = old_dim
self.new_dim = new_dim
self.normalize = normalize
assert self.new_dim < self.old_dim, "new_dim should be less than old_dim"
def call(self, input: List[Embedding]) -> List[Embedding]:
output: EmbedderOutput = deepcopy(input)
for embedding in output.data:
old_embedding = embedding.embedding
new_embedding = old_embedding[: self.new_dim]
if self.normalize:
new_embedding = normalize_vector(new_embedding)
embedding.embedding = new_embedding
return output.data
def _extra_repr(self) -> str:
repr_str = f"old_dim={self.old_dim}, new_dim={self.new_dim}, normalize={self.normalize}"
return repr_str
This output procesor will process on the data field of the EmbedderOutput, which is of type List[Embedding]. Thus we have input: List[Embedding] -> output: List[Embedding] in the call method.
Putting it all together, we can create a new embedder with the output processor.
local_embedder_256 = Embedder(
model_client=TransformersClient(),
model_kwargs=model_kwargs,
output_processors=DecreaseEmbeddingDim(768, 256),
)
print(local_embedder_256)
The structure looks like:
Embedder(
model_kwargs={'model': 'thenlper/gte-base'},
(model_client): TransformersClient()
(output_processors): DecreaseEmbeddingDim(old_dim=768, new_dim=256, normalize=True)
)
Run a query:
output = local_embedder_256(query)
print(output.length, output.embedding_dim, output.is_normalized)
# 1 256 True
ToEmbeddings¶
Once we know how to config and set up Embedder, we can use ToEmbeddings to directly convert a list of Document objects into embeddings.
from adalflow.components.data_process.data_components import ToEmbeddings
from adalflow.core.types import Document
to_embeddings = ToEmbeddings(embedder=embedder, batch_size=100)
docs = [Document(text="What is LLM?")] * 1000
output = to_embeddings(docs)
print(f"Response - Length: {len(response)})")
# 1000
[Optional]BatchEmbedder¶
Especially in data processing pipelines, you can often have more than 1000 queries to embed. We need to chunk our queries into smaller batches to avoid memory overflow.
core.embedder.BatchEmbedder is designed to handle this situation. For now, the code is rather simple, but in the future it can be extended to support multi-processing when you use AdalFlow in production data pipeline.
The BatchEmbedder orchestrates the Embedder and handles the batching process. To use it, you need to pass the Embedder and the batch size to the constructor.
from adalflow.core.embedder import BatchEmbedder
batch_embedder = BatchEmbedder(embedder=local_embedder, batch_size=100)
queries = [query] * 1000
response = batch_embedder(queries)
# 100%|██████████| 11/11 [00:04<00:00, 2.59it/s]
Note
To integrate your own embedding model or from API providers, you need to implement your own subclass of ModelClient.
References
transformers: https://huggingface.co/docs/transformers/en/index
thenlper/gte-base model: https://huggingface.co/thenlper/gte-base