
Generator¶
Generator is a user-facing orchestration component with a simple and unified interface for LLM prediction. It is a pipeline consisting of three subcomponents. By switching the prompt template, model client, and output parser, users have full control and flexibility.
Design¶
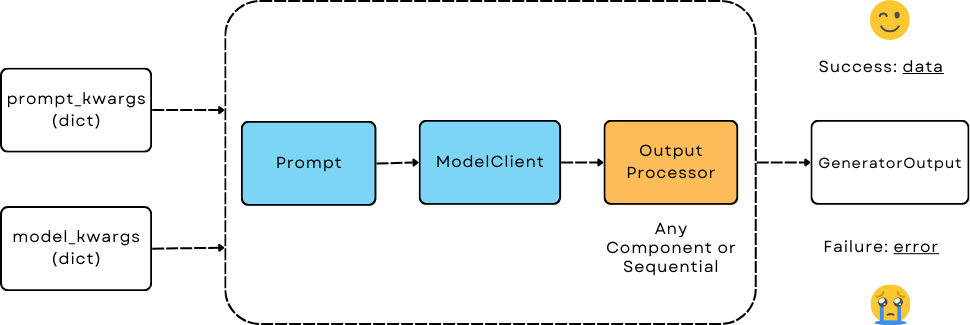
Generator - The Orchestrator for LLM Prediction¶
The Generator is designed to achieve the following goals:
Model Agnostic: The Generator should be able to call any LLM model with the same prompt.
Unified interface: It manages the pipeline from prompt (input) -> model call -> output parsing, while still giving users full control over each part.
Unified Output: This will make it easy to log and save records of all LLM predictions.
Work with Optimizer: It should be able to work with Optimizer to optimize the prompt.
The first three goals apply to other orchestrator components like Retriever, Embedder, and Agent (mostly) as well.
An Orchestrator¶
It orchestrates three components:
Prompt: by taking in
template(string) andprompt_kwargs(dict) to format the prompt at initialization. When thetemplateis not provided, it defaults toDEFAULT_ADALFLOW_SYSTEM_PROMPT.ModelClient: by taking in an already instantiated
model_clientandmodel_kwargsto call the model. Switching out the model client allows you to call any LLM model using the same prompt and output parsing.output_processors: A single component or chained components via
Sequentialto process the raw response to desired format. If no output processor provided, it is decided by the model client and often returns raw string response (from the first response message).
Call and arguments
The Generator supports both the call (__call__) and acall methods.
They take two optional arguments:
prompt_kwargs(dict): This is combined with theprompt_kwargsfrom the initialPromptcomponent and used to format the prompt.model_kwargs(dict): This is combined with themodel_kwargsfrom the initial model client, and along withModelType.LLM, it is passed to theModelClient. The ModelClient will interpret all the inputs asapi_kwargsspecific to each model API provider.
Note
This also means any ModelClient that wants to be compatible with Generator should take accept model_kwargs and model_type as arguments.
GeneratorOutput¶
Unlike other components, we cannot always enforce the LLM to follow the output format. The ModelClient and the output_processors may fail.
Note
Whenever an error occurs, we do not raise the error and force the program to stop. Instead, Generator will always return an output record. We made this design choice because it can be really helpful to log various failed cases in your train/eval sets all together for further investigation and improvement.
In particular, we created GeneratorOutput to capture important information.
data (object) : Stores the final processed response after all three components in the pipeline, indicating success.
error (str): Contains the error message if any of the three components in the pipeline fail. When this is not None, it indicates failure.
raw_response (str): Raw string response for reference of any LLM predictions. Currently, it is a string that comes from the first response message. [This might change and be different in the future]
metadata (dict): Stores any additional information
usage: Reserved for tracking the usage of the LLM prediction.
Whether to do further processing or terminate the pipeline whenever an error occurs is up to the user from here on.
Basic Generator Tutorial¶
The Generator class is the core component in AdalFlow for interacting with AI models. This tutorial covers the essential concepts and patterns.
What is a Generator?¶
A Generator is a unified interface for model interactions that:
Takes input and formats it using a prompt template
Sends the formatted input to an AI model
Returns a standardized
GeneratorOutputobject
Basic Usage¶
Here’s the simplest way to use a Generator:
from adalflow.core import Generator
from adalflow.components.model_client.openai_client import OpenAIClient
# Create a generator
gen = Generator(
model_client=OpenAIClient(),
model_kwargs={
"model": "gpt-4o-mini",
"temperature": 0.7
}
)
# Use the generator
response = gen({"input_str": "What is the capital of France?"})
print(response)
Generator In Action¶
We will create a simple one-turn chatbot to demonstrate how to use the Generator.
Minimum Example¶
The minimum setup to initiate a generator in the code:
import adalflow as adal
from adalflow.components.model_client import GroqAPIClient
generator = adal.Generator(
model_client=GroqAPIClient(),
model_kwargs={"model": "llama3-8b-8192"},
)
print(generator)
The structure of generator using print:
Generator(
model_kwargs={'model': 'llama3-8b-8192'},
(prompt): Prompt(
template:
{# task desc #}
{% if task_desc_str %}
{{task_desc_str}}
{% else %}
You are a helpful assistant.
{% endif %}
{# output format #}
{% if output_format_str %}
{{output_format_str}}
{% endif %}
{# tools #}
{% if tools_str %}
{{tools_str}}
{% endif %}
{# example #}
{% if examples_str %}
{{examples_str}}
{% endif %}
{# chat history #}
{% if chat_history_str %}
{{chat_history_str}}
{% endif %}
{#contex#}
{% if context_str %}
{{context_str}}
{% endif %}
{# steps #}
{% if steps_str %}
{{steps_str}}
{% endif %}
{% if input_str %}
{{input_str}}
{% endif %}
You:
, prompt_variables: ['input_str', 'tools_str', 'context_str', 'steps_str', 'task_desc_str', 'chat_history_str', 'output_format_str', 'examples_str']
)
(model_client): GroqAPIClient()
)
Show the Final Prompt
The Generator ‘s print_prompt method will simply relay the method from the Prompt component:
prompt_kwargs = {"input_str": "What is LLM? Explain in one sentence."}
generator.print_prompt(**prompt_kwargs)
The output will be the formatted prompt:
<User>
What is LLM? Explain in one sentence.
</User>
You:
Call the Generator
output = generator(
prompt_kwargs=prompt_kwargs,
)
print(output)
The output will be the GeneratorOutput object:
GeneratorOutput(data='LLM stands for Large Language Model, a type of artificial intelligence that is trained on vast amounts of text data to generate human-like language outputs, such as conversations, text, or summaries.', error=None, usage=None, raw_response='LLM stands for Large Language Model, a type of artificial intelligence that is trained on vast amounts of text data to generate human-like language outputs, such as conversations, text, or summaries.', metadata=None)
Use Template¶
In this example, we will use a customized template to format the prompt. We intialized the prompt with one variable task_desc_str, which is further combined with the input_str in the prompt.
template = r"""<SYS>{{task_desc_str}}</SYS>
User: {{input_str}}
You:"""
generator = Generator(
model_client=GroqAPIClient(),
model_kwargs={"model": "llama3-8b-8192"},
template=template,
prompt_kwargs={"task_desc_str": "You are a helpful assistant"},
)
prompt_kwargs = {"input_str": "What is LLM?"}
generator.print_prompt(
**prompt_kwargs,
)
output = generator(
prompt_kwargs=prompt_kwargs,
)
The final prompt is:
<SYS>You are a helpful assistant</SYS>
User: What is LLM?
You:
Note
It is quite straightforward to use any prompt.
They only need to stick to jinja2 syntax.
Use output_processors¶
In this example, we will instruct the LLM to output a JSON object in response. We will use the JsonParser to parse the output back to a dict object.
from adalflow.core import Generator
from adalflow.core.types import GeneratorOutput
from adalflow.components.model_client import OpenAIClient
from adalflow.core.string_parser import JsonParser
output_format_str = r"""Your output should be formatted as a standard JSON object with two keys:
{
"explanation": "A brief explanation of the concept in one sentence.",
"example": "An example of the concept in a sentence."
}
"""
generator = Generator(
model_client=OpenAIClient(),
model_kwargs={"model": "gpt-3.5-turbo"},
prompt_kwargs={"output_format_str": output_format_str},
output_processors=JsonParser(),
)
prompt_kwargs = {"input_str": "What is LLM?"}
generator.print_prompt(**prompt_kwargs)
output: GeneratorOutput = generator(prompt_kwargs=prompt_kwargs)
print(type(output.data))
print(output.data)
The final prompt is:
<SYS>
<OUTPUT_FORMAT>
Your output should be formatted as a standard JSON object with two keys:
{
"explanation": "A brief explanation of the concept in one sentence.",
"example": "An example of the concept in a sentence."
}
</OUTPUT_FORMAT>
</SYS>
<User>
What is LLM?
</User>
You:
The above printout is:
<class 'dict'>
{'explanation': 'LLM stands for Large Language Model, which are deep learning models trained on enormous amounts of text data.', 'example': 'An example of a LLM is GPT-3, which can generate human-like text based on the input provided.'}
Please refer to Parser for a more comprehensive guide on the Parser components.
Switch the model_client¶
Also, did you notice that we have already switched to using models from OpenAI in the above example?
This demonstrates how easy it is to switch the model_client in the Generator, making it a truly model-agnostic component.
We can even use ModelClientType to switch the model client without handling multiple imports.
from adalflow.core.types import ModelClientType
generator = Generator(
model_client=ModelClientType.OPENAI(), # or ModelClientType.GROQ()
model_kwargs={"model": "gpt-3.5-turbo"},
)
Get Errors in GeneratorOutput¶
We will use an incorrect API key to delibrately create an error.
We will still get a response, but it will only contain empty data and an error message.
Here is an example of an API key error with OpenAI:
GeneratorOutput(data=None, error="Error code: 401 - {'error': {'message': 'Incorrect API key provided: ab. You can find your API key at https://platform.openai.com/account/api-keys.', 'type': 'invalid_request_error', 'param': None, 'code': 'invalid_api_key'}}", usage=None, raw_response=None, metadata=None)
Create from Configs¶
As with all components, we can create the generator purely from configs.
Know it is a Generator
In this case, we know we are creating a generator, we will use from_config method from the Generator class.
from adalflow.core import Generator
config = {
"model_client": {
"component_name": "GroqAPIClient",
"component_config": {},
},
"model_kwargs": {
"model": "llama3-8b-8192",
},
}
generator: Generator = Generator.from_config(config)
print(generator)
prompt_kwargs = {"input_str": "What is LLM? Explain in one sentence."}
generator.print_prompt(**prompt_kwargs)
output = generator(
prompt_kwargs=prompt_kwargs,
)
print(output)
Purely from the Configs
This is even more general.
This method can be used to create any component from configs.
We just need to follow the config structure: component_name and component_config for all arguments.
from adalflow.utils.config import new_component
from adalflow.core import Generator
config = {
"generator": {
"component_name": "Generator",
"component_config": {
"model_client": {
"component_name": "GroqAPIClient",
"component_config": {},
},
"model_kwargs": {
"model": "llama3-8b-8192",
},
},
}
}
generator: Generator = new_component(config["generator"])
print(generator)
prompt_kwargs = {"input_str": "What is LLM? Explain in one sentence."}
generator.print_prompt(**prompt_kwargs)
output = generator(
prompt_kwargs=prompt_kwargs,
)
print(output)
It works exactly the same as the previous example.
We imported Generator in this case to only show the type hinting.
Note
Please refer to the configurations for more details on how to create components from configs.
Examples Across the Library¶
Besides these examples, LLM is like water, even in our library, we have components that have adpated Generator to various other functionalities.
LLMRetrieveris a retriever that uses Generator to call LLM to retrieve the most relevant documents.DefaultLLMJudgeis a judge that uses Generator to call LLM to evaluate the quality of the response.TGDOptimizeris an optimizer that uses Generator to call LLM to optimize the prompt.ReAct Agent Planneris an LLM planner that uses Generator to plan and to call functions in ReAct Agent.
Tracing¶
In particular, we provide two tracing methods to help you develop and improve the Generator:
Trace the history change (states) on prompt during your development process.
Trace all failed LLM predictions for further improvement.
As this note is getting rather long. Please refer to the tracing to learn about these two tracing methods.
Training¶
Generator in default support training mode.
It will require users to define Parameter and pass it to the prompt_kwargs.
Image Generation¶
The Generator class also supports image generation through DALL-E models. First, you need to define a Generator subclass with the correct model type:
from adalflow import Generator
from adalflow.core.types import ModelType
class ImageGenerator(Generator):
"""Generator subclass for image generation."""
model_type = ModelType.IMAGE_GENERATION
Then you can use it like this:
from adalflow import OpenAIClient
generator = ImageGenerator(
model_client=OpenAIClient(),
model_kwargs={
"model": "dall-e-3", # or "dall-e-2"
"size": "1024x1024", # "1024x1024", "1024x1792", or "1792x1024" for DALL-E 3
"quality": "standard", # "standard" or "hd" (DALL-E 3 only)
"n": 1 # Number of images (1 for DALL-E 3, 1-10 for DALL-E 2)
}
)
# Generate an image from text
response = generator(
prompt_kwargs={"input_str": "A white siamese cat in a space suit"}
)
# response.data will contain the image URL
# Edit an existing image
response = generator(
prompt_kwargs={"input_str": "Add a red hat"},
model_kwargs={
"model": "dall-e-2",
"image": "path/to/cat.png", # Original image
"mask": "path/to/mask.png" # Optional mask showing where to edit
}
)
# Create variations of an image
response = generator(
prompt_kwargs={"input_str": None}, # Not needed for variations
model_kwargs={
"model": "dall-e-2",
"image": "path/to/cat.png" # Image to create variations of
}
)
The generator supports:
Image generation from text descriptions using DALL-E 3 or DALL-E 2
Image editing with optional masking (DALL-E 2)
Creating variations of existing images (DALL-E 2)
Both local file paths and base64-encoded images
Various image sizes and quality settings
Multiple output formats (URL or base64)
The response will always be wrapped in a GeneratorOutput object, maintaining consistency with other AdalFlow operations. The generated image(s) will be available in the data field as either a URL or base64 string.
API reference