Data (Database/Pipeline)¶
The purpose of this note is to provide an overview on data, data modeling, and data storage in LLM applications along with how AdalFlow works with data. We will conver:
Data models on how to represent important data.
Data pipeline to process data in LLM applications.
Local database providing in-memory data management and storage.
Examples on working with Cloud database using fsspec and SQLAlchemy.
Note
This note focus more on dealing with data needed to perform the LLM task. Datasets, including the input and ground truth output loading and dataset will be covered in the optimizing section.
So far, we have seen how our core components like Generator, Embedder, and Retriever work without any data cache/database and enforced data format to read data from and to write data to.
However, in real-world LLM applications, we can not avoid dealing with data storage.
Our documents to retrieve context from can be large and be stored in a file system or in a database in forms of tables or graphs.
We often need to pre-process a large amount of data (like text splitting and embedding and idf in BM25) in a datapipline into a cloud database.
We need to write records, logs to files or databases for monitoring and debugging, such as the failed llm calls.
When it comes to applications where states matter, like games and chatbots, we need to store the states and conversational history.
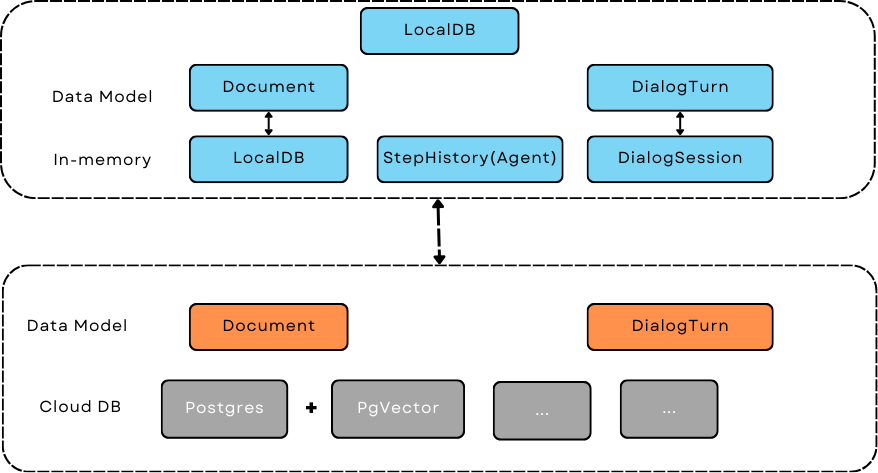
Data model and database¶
Data Models¶
Besides of having a unified GeneratorOutput, EmbedderOutput, and RetrieverOutput data format,
we provide mainly core.types.Document and core.types.DialogTurn to help with text document and conversational histor processing and data storage.
We will explain the design of Document and DialogTurn. In this note, we will continue use these simple documents we used in the previous notes:
org_documents =[
{
"title": "The Impact of Renewable Energy on the Economy",
"content": "Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure."
},
{
"title": "Understanding Solar Panels",
"content": "Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels."
},
{
"title": "Pros and Cons of Solar Energy",
"content": "While solar energy offers substantial environmental benefits, such as reducing carbon footprints and pollution, it also has downsides. The production of solar panels can lead to hazardous waste, and large solar farms require significant land, which can disrupt local ecosystems."
},
{
"title": "Renewable Energy and Its Effects",
"content": "Renewable energy sources like wind, solar, and hydro power play a crucial role in combating climate change. They do not produce greenhouse gases during operation, making them essential for sustainable development. However, the initial setup and material sourcing for these technologies can still have environmental impacts."
}
]
turns = [
{
"user": "What are the benefits of renewable energy?",
"system": "I can see you are interested in renewable energy. Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.",
"user_time": "2021-09-01T12:00:00Z",
"system_time": "2021-09-01T12:00:01Z"
},
{
"user": "How do solar panels impact the environment?",
"system": "Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.",
"user_time": "2021-09-01T12:00:02Z",
"system_time": "2021-09-01T12:00:03Z"
}
]
Document¶
The core.types.Document is used as Document data structure and to assist text processing in LLM applications.
A general document/text container with fields
text,meta_data, andid.Assist text splitting with fields
parent_doc_idandorder.Assist embedding with fields
vector.Assist using it as a prompt for LLM with fields
estimated_num_tokens.
This is why data processing components like TextSplitter and ToEmbeddings requires Document as input of each data item.
Create a Document
from adalflow.core.types import Document
documents = [Document(text=doc['content'], meta_data={'title': doc['title']}) for doc in org_documents]
print(documents)
The printout will be:
[Document(id=73c12be3-7844-435b-8678-2e8e63041698, text='Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute...', meta_data={'title': 'The Impact of Renewable Energy on the Economy'}, vector=[], parent_doc_id=None, order=None, score=None), Document(id=7a17ed45-569a-4206-9670-5316efd58d58, text='Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock ele...', meta_data={'title': 'Understanding Solar Panels'}, vector=[], parent_doc_id=None, order=None, score=None), Document(id=bcbc6ff9-518a-405a-8b0d-840021aa1953, text='While solar energy offers substantial environmental benefits, such as reducing carbon footprints and...', meta_data={'title': 'Pros and Cons of Solar Energy'}, vector=[], parent_doc_id=None, order=None, score=None), Document(id=ec910402-f98f-4077-a958-7335e34ee0c6, text='Renewable energy sources like wind, solar, and hydro power play a crucial role in combating climate ...', meta_data={'title': 'Renewable Energy and Its Effects'}, vector=[], parent_doc_id=None, order=None, score=None)]
DialogTurn¶
The core.types.DialogTurn is only used as a data structure to a user-assistant conversation turn in LLM applications.
If we need to apply a text processing pipeline to a conversational history, we will use our text container``Document`` to store the text we need to use.
Note
For both Document and DialogTurn, we have an equivalent class in database.sqlalchemy.model`(:class:`database.sqlalchemy.modoel.Document) to handle the persitence of data in a SQL database.
Here is how to get a list of DialogTurn from the turns:
from adalflow.core.types import DialogTurn, UserQuery, AssistantResponse
dialog_turns = [
DialogTurn(
user_query=UserQuery(query_str=turn["user"]),
assistant_response=AssistantResponse(response_str=turn["system"]),
user_query_timestamp=turn["user_time"],
assistant_response_timestamp=turn["system_time"],
)
for turn in turns
]
print(dialog_turns)
The printout will be:
[DialogTurn(id='f2eddc77-4667-43f5-87e0-fd11f12958b3', user_id=None, session_id=None, order=None, user_query=UserQuery(query_str='What are the benefits of renewable energy?', metadata=None), assistant_response=AssistantResponse(response_str='I can see you are interested in renewable energy. Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.', metadata=None), user_query_timestamp='2021-09-01T12:00:00Z', assistant_response_timestamp='2021-09-01T12:00:01Z', metadata=None, vector=None), DialogTurn(id='b2dbdf2f-f513-493d-aaa8-c77c98ac260f', user_id=None, session_id=None, order=None, user_query=UserQuery(query_str='How do solar panels impact the environment?', metadata=None), assistant_response=AssistantResponse(response_str='Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.', metadata=None), user_query_timestamp='2021-09-01T12:00:02Z', assistant_response_timestamp='2021-09-01T12:00:03Z', metadata=None, vector=None)]
Data Pipeline¶
Let’s see how to can write a data pipeline that can process any form of text data by using intermediate data model-Document.
Currently, we have two data processing components: TextSplitter and ToEmbeddings in the components.data_process module.
We will use ord_documents and a list of DialogTurn as examples. As our data pipelines are designed to work with Document structure,
we simplify just need to add a mapping function to convert the original data to Document.
# mapping function for org_documents
def map_to_document(doc: Dict) -> Document:
return Document(text=doc['content'], meta_data={'title': doc['title']})
def map_dialogturn_to_document(turn: DialogTurn) -> Document:
# it can be important to keep the original data's id
return Document(id=turn.id, text=turn.user_query.query_str + ' ' + turn.assistant_response.response_str)
You can refer to Text Splitter for more details on how to use TextSplitter.
ToEmbeddings is an orchestrator on BatchEmbedder and it will generate embeddings for a list of Document and store the embeddings as List[Float] in the vector field of each Document.
Sequential can be easily used to chain multiple data processing components together.
Here is the code to form a data pipeline:
from adalflow.core.embedder import Embedder
from adalflow.core.types import ModelClientType
from adalflow.components.data_process import TextSplitter, ToEmbeddings
from adalflow.core.component import Sequential
model_kwargs = {
"model": "text-embedding-3-small",
"dimensions": 256,
"encoding_format": "float",
}
splitter_config = {
"split_by": "word",
"split_length": 50,
"split_overlap": 10
}
splitter = TextSplitter(**splitter_config)
embedder = Embedder(model_client =ModelClientType.OPENAI(), model_kwargs=model_kwargs)
embedder_transformer = ToEmbeddings(embedder, batch_size=2)
data_transformer = Sequential(splitter, embedder_transformer)
print(data_transformer)
The printout will be:
Sequential(
(0): TextSplitter(split_by=word, split_length=50, split_overlap=10)
(1): ToEmbeddings(
batch_size=2
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
(batch_embedder): BatchEmbedder(
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
)
)
)
Now, apply the data pipeline to the dialog_turns:
dialog_turns_as_documents = [map_dialogturn_to_document(turn) for turn in dialog_turns]
print(dialog_turns_as_documents)
# apply data transformation to the documents
output = data_transformer(dialog_turns_as_documents)
print(output)
The printout will be:
[Document(id=e3b48bcc-df68-43a4-aa81-93922b619293, text='What are the benefits of renewable energy? I can see you are interested in renewable energy. Renewab...', meta_data=None, vector=[], parent_doc_id=None, order=None, score=None), Document(id=21f0385d-d19a-442f-ae99-910e984cdb65, text='How do solar panels impact the environment? Solar panels convert sunlight into electricity by allowi...', meta_data=None, vector=[], parent_doc_id=None, order=None, score=None)]
Splitting documents: 100%|██████████| 2/2 [00:00<00:00, 609.37it/s]
Batch embedding documents: 100%|██████████| 2/2 [00:00<00:00, 3.79it/s]
Adding embeddings to documents from batch: 2it [00:00, 10205.12it/s]
[Document(id=e636facc-8bc3-483b-afbd-37e1d8ff0526, text='What are the benefits of renewable energy? I can see you are interested in renewable energy. Renewab...', meta_data=None, vector='len: 256', parent_doc_id=e3b48bcc-df68-43a4-aa81-93922b619293, order=0, score=None), Document(id=06ea7cea-c4e4-4f5f-b3e9-2e6f4452827b, text='and installation sectors. The growth in renewable energy usage boosts local economies through increa...', meta_data=None, vector='len: 256', parent_doc_id=e3b48bcc-df68-43a4-aa81-93922b619293, order=1, score=None), Document(id=0018af12-c8fc-49ff-ab64-a2acf8ba4c27, text='How do solar panels impact the environment? Solar panels convert sunlight into electricity by allowi...', meta_data=None, vector='len: 256', parent_doc_id=21f0385d-d19a-442f-ae99-910e984cdb65, order=0, score=None), Document(id=c5431397-2a78-4870-abce-353b738c1b71, text='has been found to have a significant positive effect on the environment by reducing the reliance on ...', meta_data=None, vector='len: 256', parent_doc_id=21f0385d-d19a-442f-ae99-910e984cdb65, order=1, score=None)]
Local database¶
LocalDB class
core.db.LocalDB is a powerful data management class:
It manages a sequence of data items of any data type with CRUD operations.
Keep track and apply data transfomation/processing pipelines to its items.
Save and load the state of the items to/from a file, including all data and data transformer records.
This table lists its attributes and important methods:
Attribute/Method |
Description |
|
|---|---|---|
Attributes |
|
The name of the database. |
|
A list of items in the database. |
|
|
A dictionary to store the transformed items. |
|
|
A dictionary to store the transformer setups. |
|
|
A dictionary to store the mapping functions used together with transformer. |
|
Data CRUD Operations |
|
Load a list of items to the database |
|
Add items to the end of |
|
|
Add a single item by index or append to the end. Optionally apply the transformer. |
|
|
Remove items by index or pop the last item. Optionally remove the transformed data as well. Assume the transformed item has the same index as the original item. Might not always be the case. |
|
|
Reset all attributes to the initial state. |
|
Data Processing |
|
Register a data transformation to the database to be used later. |
|
Apply a transformer by key to the data. |
|
|
Register and apply a transformer to the data. |
|
Data Persistence |
|
Save the state of the database to a pickle file. |
|
A class method to load the state of the database from a pickle file. |
Now, finally, we have a good way to organize important data along its pipeline like Document and DialogTurn in a database.
Data Loading and CRUD Operations
Let’s create a LocalDB to manage the dialog_turns and its data processing pipeline:
from adalflow.core.db import LocalDB
dialog_turn_db = LocalDB('dialog_turns')
print(dialog_turn_db)
dialog_turn_db.load(dialog_turns)
print(dialog_turn_db)
The printout will be:
LocalDB(name='dialog_turns', items=[], transformed_items={}, transformer_setups={}, mapper_setups={})
LocalDB(name='dialog_turns', items=[DialogTurn(id='f2eddc77-4667-43f5-87e0-fd11f12958b3', user_id=None, session_id=None, order=None, user_query=UserQuery(query_str='What are the benefits of renewable energy?', metadata=None), assistant_response=AssistantResponse(response_str='I can see you are interested in renewable energy. Renewable energy technologies not only help in reducing greenhouse gas emissions but also contribute significantly to the economy by creating jobs in the manufacturing and installation sectors. The growth in renewable energy usage boosts local economies through increased investment in technology and infrastructure.', metadata=None), user_query_timestamp='2021-09-01T12:00:00Z', assistant_response_timestamp='2021-09-01T12:00:01Z', metadata=None, vector=None), DialogTurn(id='b2dbdf2f-f513-493d-aaa8-c77c98ac260f', user_id=None, session_id=None, order=None, user_query=UserQuery(query_str='How do solar panels impact the environment?', metadata=None), assistant_response=AssistantResponse(response_str='Solar panels convert sunlight into electricity by allowing photons, or light particles, to knock electrons free from atoms, generating a flow of electricity. Solar panels are a type of renewable energy technology that has been found to have a significant positive effect on the environment by reducing the reliance on fossil fuels.', metadata=None), user_query_timestamp='2021-09-01T12:00:02Z', assistant_response_timestamp='2021-09-01T12:00:03Z', metadata=None, vector=None)], transformed_items={}, transformer_setups={}, mapper_setups={})
Data Processing/Transformation Pipeline(such as TextSplitter and Embedder)
We register and apply the transformer from the last section to the data stored in the dialog_turn_db:
key = "split_and_embed"
dialog_turn_db.transform(data_transformer, map_fn=map_dialogturn_to_document, key=key)
print(dialog_turn_db.transformed_items[key])
print(dialog_turn_db.transformer_setups[key])
print(dialog_turn_db.mapper_setups[key])
The printout will be:
Splitting documents: 100%|██████████| 2/2 [00:00<00:00, 2167.04it/s]
Batch embedding documents: 100%|██████████| 2/2 [00:00<00:00, 5.46it/s]
Adding embeddings to documents from batch: 2it [00:00, 63072.24it/s]
[Document(id=64987b2b-b6c6-4eb4-9122-02448e3fd394, text='What are the benefits of renewable energy? I can see you are interested in renewable energy. Renewab...', meta_data=None, vector='len: 256', parent_doc_id=f2eddc77-4667-43f5-87e0-fd11f12958b3, order=0, score=None), Document(id=9a424d4c-4bd0-48ce-aba9-7a4f86892556, text='and installation sectors. The growth in renewable energy usage boosts local economies through increa...', meta_data=None, vector='len: 256', parent_doc_id=f2eddc77-4667-43f5-87e0-fd11f12958b3, order=1, score=None), Document(id=45efa517-8e52-4780-bdbd-2329ffa8d4b6, text='How do solar panels impact the environment? Solar panels convert sunlight into electricity by allowi...', meta_data=None, vector='len: 256', parent_doc_id=b2dbdf2f-f513-493d-aaa8-c77c98ac260f, order=0, score=None), Document(id=bc0ff7f6-27cc-4e24-8c3e-9435ed755e20, text='has been found to have a significant positive effect on the environment by reducing the reliance on ...', meta_data=None, vector='len: 256', parent_doc_id=b2dbdf2f-f513-493d-aaa8-c77c98ac260f, order=1, score=None)]
Sequential(
(0): TextSplitter(split_by=word, split_length=50, split_overlap=10)
(1): ToEmbeddings(
batch_size=2
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
(batch_embedder): BatchEmbedder(
(embedder): Embedder(
model_kwargs={'model': 'text-embedding-3-small', 'dimensions': 256, 'encoding_format': 'float'},
(model_client): OpenAIClient()
)
)
)
)
<function map_dialogturn_to_document at 0x10fb26f20>
Save/Reload Data
dialog_turn_db.save_state(filepath='.storage/dialog_turns.pkl')
reloaded_dialog_turn_db = LocalDB.load_state(filepath='.storage/dialog_turns.pkl')
print(str(dialog_turn_db.__dict__) == str(restored_dialog_turn_db.__dict__))
This will print True if the two databases are the same. We can use the reloaded db class to continue to work with the data.
This data class can be really helpful for researchers and developers to run and track local experiments to optimize the data processing pipelines
CRUD Operations using with Generator for a conversation
We will have a chatbot and add new conversation turns to the database. When the conversation is too long to fit into token limit of your LLM model, you can easily use a retriever to control the conversation history length.
First, let us prepare the generator. We will use input_str and chat_history_str from our default prompt.
This will also leverage DialogTurn ‘s inheritant ability from DataClass to quickly form the chat_history_str.
from adalflow.core import Generator
llm_kwargs = {
"model": "gpt-3.5-turbo"
}
generator = Generator(model_client = ModelClientType.OPENAI(), model_kwargs=llm_kwargs)
Here is the code to form the prompt and we will use generator.print_prompt() to check how the prompt will look like:
from typing import List
input_str = "What are the benefits of renewable energy? Did I ask this before?"
def format_chat_history_str(turns: List[DialogTurn]) -> str:
chat_history_str = []
for turn in turns:
chat_history_str.append(
turn.to_yaml(
exclude=[
"id",
"user_id",
"session_id",
"user_query_timestamp",
"assistant_response_timestamp",
"order",
"metadata",
"vector",
],
)
)
chat_history_str = '\n_________\n'.join(chat_history_str)
return chat_history_str
chat_history_str = format_chat_history_str(dialog_turn_db.items[0:1])
print(generator.print_prompt(input_str=input_str, chat_history_str=chat_history_str))
The printout will be:
Prompt:
<SYS>
<CHAT_HISTORY>
user_query:
metadata: null
query_str: What are the benefits of renewable energy?
assistant_response:
metadata: null
response_str: I can see you are interested in renewable energy. Renewable energy technologies
not only help in reducing greenhouse gas emissions but also contribute significantly
to the economy by creating jobs in the manufacturing and installation sectors. The
growth in renewable energy usage boosts local economies through increased investment
in technology and infrastructure
</CHAT_HISTORY>
</SYS>
<User>
What are the benefits of renewable energy? Did I ask this before?
</User>
You:
Now, let us chat with the generator and add the conversation turns to the database:
response = generator(prompt_kwargs={"input_str": input_str, "chat_history_str": chat_history_str})
print(response)
# add the turn and apply the transformer
new_turn = DialogTurn(
user_query=UserQuery(query_str=input_str),
assistant_response=AssistantResponse(response_str=response.data),
)
dialog_turn_db.add(new_turn, apply_transformer=True)
print(dialog_turn_db.length, len(dialog_turn_db.transformed_items[key]))
# 3 6
Use With Retriever
Assume our history is getting too long to fit into the token limit.
We will use a semantic retriever to fetch relevant chunked documents from the database.
Then, instead of directly using the documents, we will find its relevant dialog turns by comparing the parent_doc_id with the id of the document.
Here is the code to prepare the relevant dialog turns.
from adalflow.components.retriever.faiss_retriever import FAISSRetriever
retriever = FAISSRetriever(top_k=3, embedder=embedder)
embeddings = [item.vector for item in dialog_turn_db.transformed_items[key]]
retriever.build_index_from_documents(documents=embeddings)
# get the relevant documents
top_k_documents = retriever(input=input_str)
# get the relevant dialog turns
parent_doc_ids = set(
[
dialog_turn_db.transformed_items[key][doc_index].parent_doc_id
for doc_index in top_k_documents[0].doc_indices
]
)
condition_fn = lambda item: item.id in parent_doc_ids
fetched_dialog_turns = [item for item in dialog_turn_db.items if condition_fn(item)]
Now, we can use the fetched_dialog_turns to continue the conversation with the generator.
Cloud database¶
Please check out the Retriever for using Cloud database as a storage and a retriever.
File Reading¶
We dont provide integration currently, but using file reading packages like fsspec should be fairly easy to use with our data processing pipeline.
API References
Additional Resources