
Generator¶
Introduction¶
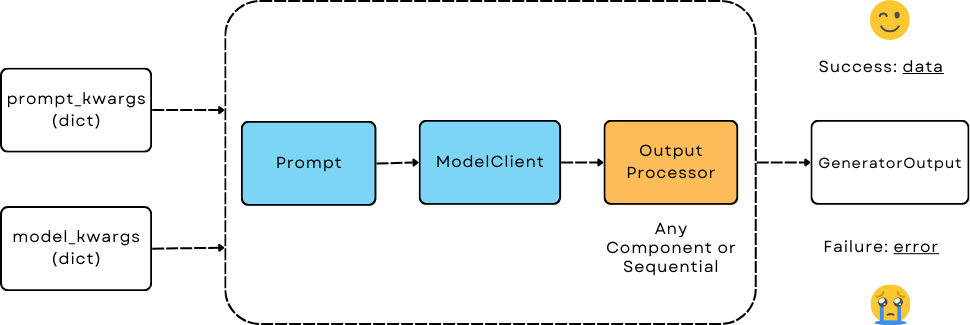
Generator - The Orchestrator for LLM Prediction¶
Generator is the most important computation unit in AdalFlow:
It orchestrates and unifies Prompt, ModelClient (model provider apis), and output_processors (parser and structured output) to achieve functionalities such as reasoning, structured output, tool usage, code generation. With these functionalities, developers can program it to be any LLM applications, from chatbots(with or w.o memory), RAG, to agents.
It is a GradComponnent that has both forward and backward methods. Developers can optimize the prompt when it is defined as a Parameter and being used together with Trainer.
Generator has three desirable properties:
Model Agnostic: The Generator levarages a standard interface–ModelClient–to interact with different LLM models. This makes it easy to switch between different models simply via configuration.
Full Controllable and Transparent Prompt: Unlike many libraries where users can only customize an instruction, we allow users to define their own prompt template with Jinja2 that comes with customized parameters to fill in. These parameters in the prompt can be further optimized end to end.
Unified Output: With
GeneratorOutput, we ensure it can capture the final parsed output indata, any error message inerror, and the raw response inraw_response.idandusageare also included for tracking purposes.
Note
Users should decide what to do when the error occurs.
Basic Usage¶
Using the Generator is simple:
from adalflow.core import Generator
from adalflow.components.model_client.openai_client import OpenAIClient
llm = Generator(
model_client=OpenAIClient(),
model_kwargs={
"model": "o3-mini",
}
)
prompt_kwargs = {"input_str": "What is LLM?"}
response = llm(prompt_kwargs=prompt_kwargs) # or llm.call in eval and llm.forward in training
print(response)
The generator comes with a default prompt template DEFAULT_ADALFLOW_SYSTEM_PROMPT, which can be replaced by user’s own template with Jinja2 syntax.
Here is the printout of the GeneratorOutput:
GeneratorOutput(id=None, data='LLM most commonly stands for "Large Language Model." This is a type of artificial intelligence system that has been trained on vast amounts of text data to understand, generate, and interact using human language. Here are some key points about LLMs:\n\n• They use advanced deep learning techniques (often based on the Transformer architecture) to learn patterns, grammar, context, and semantics in language.\n• Examples of LLMs include models like OpenAI’s GPT series, Google’s BERT, and others.\n• They can perform a wide range of language tasks such as answering questions, summarizing documents, translating languages, writing creative content, and more.\n\nIt’s worth noting that in other contexts, "LLM" might also refer to a Master of Laws degree. However, in discussions related to AI and natural language processing, LLM almost always refers to a Large Language Model.', error=None, usage=CompletionUsage(completion_tokens=570, prompt_tokens=45, total_tokens=615), raw_response='LLM most commonly stands for "Large Language Model." This is a type of artificial intelligence system that has been trained on vast amounts of text data to understand, generate, and interact using human language. Here are some key points about LLMs:\n\n• They use advanced deep learning techniques (often based on the Transformer architecture) to learn patterns, grammar, context, and semantics in language.\n• Examples of LLMs include models like OpenAI’s GPT series, Google’s BERT, and others.\n• They can perform a wide range of language tasks such as answering questions, summarizing documents, translating languages, writing creative content, and more.\n\nIt’s worth noting that in other contexts, "LLM" might also refer to a Master of Laws degree. However, in discussions related to AI and natural language processing, LLM almost always refers to a Large Language Model.', metadata=None)
Here is how you can print out the prompt:
llm.print_prompt(**prompt_kwargs)
Now, let’s use a simple and customized template to perform a task of counting objects:
import adalflow as adal
# the template has three variables: system_prompt, few_shot_demos, and input_str
few_shot_template = r"""<START_OF_SYSTEM_PROMPT>
{{system_prompt}}
{# Few shot demos #}
{% if few_shot_demos is not none %}
Here are some examples:
{{few_shot_demos}}
{% endif %}
<END_OF_SYSTEM_PROMPT>
<START_OF_USER>
{{input_str}}
<END_OF_USER>
"""
object_counter = Generator(
model_client=adal.GroqAPIClient(),
model_kwargs={
"model": "llama3-8b-8192",
},
template=few_shot_template,
prompt_kwargs={
"system_prompt": "You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.",
}
)
question = "I have a flute, a piano, a trombone, four stoves, a violin, an accordion, a clarinet, a drum, two lamps, and a trumpet. How many musical instruments do I have?"
response = object_counter(prompt_kwargs={"input_str": question})
print(response)
prompt = object_counter.print_prompt(input_str=question)
print(prompt)
The output will be:
GeneratorOutput(id=None, data="I'll think step by step!\n\nI'm given a list of items, and I need to identify the musical instruments. Let's go through the list:\n\n* Flute: yes, it's a musical instrument\n* Piano: yes, it's a musical instrument\n* Trombone: yes, it's a musical instrument\n* Violin: yes, it's a musical instrument\n* Accordion: yes, it's a musical instrument\n* Clarinet: yes, it's a musical instrument\n* Drum: yes, it's a musical instrument\n* Trumpet: yes, it's a musical instrument\n\nI've identified 8 musical instruments so far.\n\nNow, let's check if there are any non-musical items on the list:\n\n* Four stoves: no, these are not musical instruments\n* Two lamps: no, these are not musical instruments\n\nSo, I've identified all the musical instruments, and I'm done.\n\nAnswer: 8", error=None, usage=CompletionUsage(completion_tokens=198, prompt_tokens=116, total_tokens=314), raw_response="I'll think step by step!\n\nI'm given a list of items, and I need to identify the musical instruments. Let's go through the list:\n\n* Flute: yes, it's a musical instrument\n* Piano: yes, it's a musical instrument\n* Trombone: yes, it's a musical instrument\n* Violin: yes, it's a musical instrument\n* Accordion: yes, it's a musical instrument\n* Clarinet: yes, it's a musical instrument\n* Drum: yes, it's a musical instrument\n* Trumpet: yes, it's a musical instrument\n\nI've identified 8 musical instruments so far.\n\nNow, let's check if there are any non-musical items on the list:\n\n* Four stoves: no, these are not musical instruments\n* Two lamps: no, these are not musical instruments\n\nSo, I've identified all the musical instruments, and I'm done.\n\nAnswer: 8", metadata=None)
The prompt will be:
<START_OF_SYSTEM_PROMPT>
You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.
<END_OF_SYSTEM_PROMPT>
<START_OF_USER>
I have a flute, a piano, a trombone, four stoves, a violin, an accordion, a clarinet, a drum, two lamps, and a trumpet. How many musical instruments do I have?
<END_OF_USER>
In the next section, we will introduce more advanced features such as structured output, tool usage, and defining trainable prompts.
Structured Output¶
First, in the object count example, we want to extract the answer which ideally should be converted to integer. The best way to do this is to customize a parser that will leverage regular expressions to extract the answer.
import re
@adal.func_to_data_component
def parse_integer_answer(answer: str):
try:
numbers = re.findall(r"\d+", answer)
if numbers:
answer = int(numbers[-1])
else:
answer = -1
except ValueError:
answer = -1
return answer
object_counter = Generator(
model_client=adal.GroqAPIClient(),
model_kwargs={
"model": "llama3-8b-8192",
},
template=few_shot_template,
prompt_kwargs={
"system_prompt": "You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.",
},
output_processors=parse_integer_answer,
)
response = object_counter(prompt_kwargs={"input_str": question})
print(response)
print(type(response.data))
The output will be:
GeneratorOutput(id=None, data=7, error=None, usage=CompletionUsage(completion_tokens=69, prompt_tokens=116, total_tokens=185), raw_response='The problem asks me to count the number of musical instruments.\n\nI will list down all the instruments I have:\n\n1. Flute\n2. Piano\n3. Trombone\n4. Violin\n5. Accordion\n6. Clarinet\n7. Trumpet\n\nThere are 7 musical instruments. \n\nAnswer: 7', metadata=None)
<class 'int'>
The data field now is an integer instead of the whole string output. But you can still find all string response from raw_response.
Now, we can achieve the same result via more advanced data structure.
We will leverage DataClass to define a structured output with two fields: thought and answer.
Then, we leverage DataClassParser to parse the output back to the structured data.
# 1. add an output_format_str variable in the template
template = r"""<START_OF_SYSTEM_PROMPT>
{{system_prompt}}
<OUTPUT_FORMAT>
{{output_format_str}}
</OUTPUT_FORMAT>
<END_OF_SYSTEM_PROMPT>
<START_OF_USER>
{{input_str}}
<END_OF_USER>"""
# 2. define the structured output
from dataclasses import dataclass, field
@dataclass
class QAOutput(DataClass):
thought: str = field(
metadata={
"desc": "Your thought process for the question to reach the answer."
}
)
answer: int = field(metadata={"desc": "The answer to the question."})
__output_fields__ = ["thought", "answer"]
# 3. define the parser
parser = adal.DataClassParser(
data_class=QAOutput, return_data_class=True, format_type="json"
)
object_counter = Generator(
model_client=adal.GroqAPIClient(),
model_kwargs={
"model": "llama3-8b-8192",
},
template=template,
prompt_kwargs={
"system_prompt": "You will answer a reasoning question. Think step by step. ",
"output_format_str": parser.get_output_format_str(), # 4. add the output_format_str in the prompt_kwargs
},
output_processors=parser, # 5. add the parser as the output_processors
)
response = object_counter(prompt_kwargs={"input_str": question})
print(response)
object_counter.print_prompt(input_str=question)
The output will be:
GeneratorOutput(id=None, data=customize_template.<locals>.QAOutput(thought="First, I'll identify the musical instruments in my list. I see flute, piano, trombone, violin, accordion, clarinet, and trumpet, which are all musical instruments. Then, I will count them to find out how many I have. Flute, piano, trombone, violin, accordion, clarinet, and trumpet makes a total of 7 musical instruments.", answer=7), error=None, usage=CompletionUsage(completion_tokens=94, prompt_tokens=229, total_tokens=323), raw_response='```\n{\n "thought": "First, I\'ll identify the musical instruments in my list. I see flute, piano, trombone, violin, accordion, clarinet, and trumpet, which are all musical instruments. Then, I will count them to find out how many I have. Flute, piano, trombone, violin, accordion, clarinet, and trumpet makes a total of 7 musical instruments.",\n "answer": 7\n}', metadata=None)
Prompt:
______________________
<START_OF_SYSTEM_PROMPT>
You will answer a reasoning question. Think step by step.
<OUTPUT_FORMAT>
Your output should be formatted as a standard JSON instance with the following schema:
```
{
"thought": "Your thought process for the question to reach the answer. (str) (required)",
"answer": "The answer to the question. (int) (required)"
}
```
-Make sure to always enclose the JSON output in triple backticks (```). Please do not add anything other than valid JSON output!
-Use double quotes for the keys and string values.
-DO NOT mistaken the "properties" and "type" in the schema as the actual fields in the JSON output.
-Follow the JSON formatting conventions.
</OUTPUT_FORMAT>
<END_OF_SYSTEM_PROMPT>
<START_OF_USER>
I have a flute, a piano, a trombone, four stoves, a violin, an accordion, a clarinet, a drum, two lamps, and a trumpet. How many musical instruments do I have?
<END_OF_USER>
From the response we can get QAOutput in the data field, which is a structured output with two fields: thought as string and answer as integer.
The way we achieve this is via the DataClassParser’s built-in prompt formatting (via output_format_str variable in the prompt) and parsing as the output_processors.
We allow developers to do very complicated data structure and even multi-level of nested data structure. Check out this colab example for more details.
Trainable Prompt as Parameter¶
To train the prompt, developers need to define it as Parameter.
For example, if we want to prompt tune the system_prompt in the object counter example, this is what we do instead:
from adalflow.optim.parameter import ParameterType
system_prompt = adal.Parameter(
data="You will answer a reasoning question. Think step by step. The last line of your response should be of the following format: 'Answer: $VALUE' where VALUE is a numerical value.",
role_desc="To give task instruction to the language model in the system prompt",
requires_opt=True,
param_type=ParameterType.PROMPT, # leverages LLM-AutoDiff to optimize the prompt
instruction_to_optimizer="You can try to show examples to see if it helps.",
)
If you want to also leverage Few-shot learning, you can define the few_shot_demos as another parameter:
few_shot_demos = adal.Parameter(
data=None,
role_desc="To provide few shot demos to the language model",
requires_opt=True,
param_type=ParameterType.DEMOS,
)
And then you can pass these parameters to the prompt_kwargs:
prompt_kwargs={
"system_prompt": system_prompt,
"few_shot_demos": few_shot_demos,
}
By doing so, the trainer will automatically detect these parameters and optimize them accordingly.
Tool¶
LM can use tools in the same way how we did the structured output.
We will need a convenient way to describe each tool or function in the prompt and instruct it using the output_format_str to manage the function calls.
We have to manage some context variables to achieve the function call.
You can check out Tool for more details.
Examples Across the Library¶
Besides these examples, LLM is like water, even in our library, we have components that have adpated Generator to various other functionalities.
LLMRetrieveris a retriever that uses Generator to call LLM to retrieve the most relevant documents.DefaultLLMJudgeis a judge that uses Generator to call LLM to evaluate the quality of the response.TGDOptimizeris an optimizer that uses Generator to call LLM to optimize the prompt.ReAct Agent Planneris an LLM planner that uses Generator to plan and to call functions in ReAct Agent.
API reference